(IROS2021)SOIL
因为灵巧手的操作的domain相对复杂,所以需要引入专家示教的方式要诱导分布。但是通常情况下,在现实世界中,要得到state-action pair是比较困难的,比如从视频中学习。所以这篇文章就训练了一个inverse dynamics model(反向动态模型)来从状态转移中预测对应的动作。
首先,传统的逆向动力学(Robotic Inverse Dynamics)的概念为:已知某一时刻机器人各关节的位置$q$,关节速度$\dot{q}$以及关节加速度$\ddot{q}$,求此时施加在机器人各杆件上的驱动力(力矩)$\tau$。
而在模仿学习中,反向动态模型(Inverse Dynamics model)指的是从状态转移$\{S_t,S_{t+1}\}$到动作$A_t$的映射。
论文给了RL和模仿学习的定义,此处再回顾一下:
普通策略梯度算法
$$
g=\sum_{(s,a)\in\pi}\nabla_{\theta}\log\pi_{\theta}(a|s)A^{\pi}(s,a)
$$
其中的$A^{\pi}(s,a)$是advantage function。
DAPG算法
我们可以使用示教的方式来加速收敛。示教以state-action pair的形式输入,可以使用DAPG(demo augmented policy gradient)算法。DAPG把原先的策略梯度上添加了一项辅助的模仿项(auxiliary imitation form),也就是:
$$
g_{dapg}=g+\lambda_0\lambda_1^k\sum_{(s,a)\in D}\nabla_{\theta}\log\pi_{\theta}(a|s)
$$
其中D是state-action示教,而$\lambda_0$和$\lambda_1$是尺度化的超参数来控制模仿学习目标的相对贡献。
Problem
我们假设模型可以直接访问到灵巧手的关节角度、对应的力、关节的速度。我们也会提供物体的位置。这允许我们单纯地研究state-only imitation learning,而不去纠结一些state estimation的内容。
注意到我们此时的示教内容只有state序列$\{s_i\}_{i=0}^T$,所以论文提出了反向动态模型来对$s_t$和$s_{t+1}$之间的action $a_t$做估计,如下图所示:
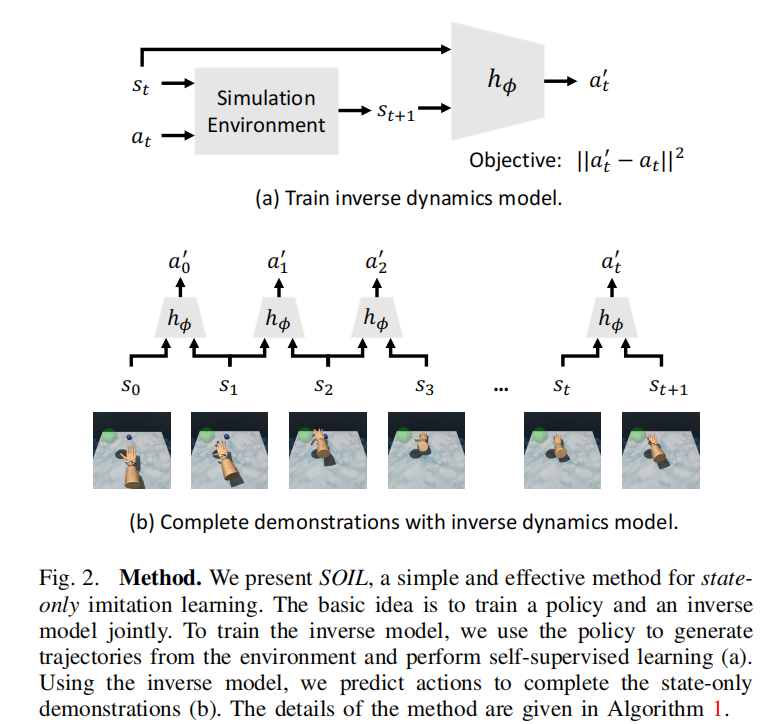
(a)图就是反向动态模型的结构,也就是从仿真器中收集到$(s_{t}, s_{t+1}, a_{t})$三元组作为GT,训练一个输入两个state,预测$a_t’$的模型。(b)图就是在说,我们有了反向动力学模型后,只需要在示教数据集上做一遍inference就可以得到state-action demonstration,放到DPAG中进行训练。
所以为了训练反向动态模型,我们需要在仿真器中收集足够多的$(s_{t}, s_{t+1}, a_{t})$来训练,但是如果我们在仿真器中使用初始策略随机采集轨迹的话,由于action空间是非常大的,所以效果会很差。我们需要有一个办法来探索action空间,使其往高目标价值函数方向优化。这就是为什么我们在SOIL算法中每一次都是用当前策略$\pi_{\theta}$下收集的轨迹来训练我们的反向动态模型。因为我们认为专家示教是相对于一系列高reward function的action。迭代可以保证策略逐步收敛,也就是我们的$\pi_{\theta}$正在逐渐接近我们的示教策略。这样的话,对示教动作的估计会越来越精准。
| Algorithm: State-Only Imitation Learning(SOIL) |
|---|
| $\textbf{Input:}$ Inverse model $h$, Policy $\pi$, Replay buffer $R$, State-Only Demonstration D. $\textbf{Initialize:}$ Learnable parameters $\phi$ for $h_{\phi}$, $\theta$ for $\pi_{\theta}$. $\textbf{for}$ i = 1,2,…,$N_{iter}$ $\textbf{do}$ $\ \ \ \ $# 收集轨迹 $\ \ \ \ $$\tau_i\equiv \{s_t,a_t,s_{t+1}, r_t\}_i\sim\pi_{\theta} $ $\ \ \ \ $# 添加轨迹到Replay Buffer中 $\ \ \ \ $$\textbf{for}$ j = 1,2,…,$N_{inv}$ $\textbf{do}$ $\ \ \ \ \ \ \ \ $# 从Replay Buffer中采样GT,因为这是在仿真器里收集的,所以是有state和action的 tuple。 $\ \ \ \ \ \ \ \ $$B_j\equiv \{s_t,a_t,s_{t+1}\}_j\sim R$ $\ \ \ \ \ \ \ \ $# 更新我们的inverse dynamics模型 $\ \ \ \ \ \ \ \ $$\phi\leftarrow \text{InvOpt}(B_j;\phi)$ $\ \ \ \ $$\textbf{end for}$ $\ \ \ \ $# 使用inverse model来预测纯状态示教中的actions $\ \ \ \ $$D’\leftarrow 使用最新的模型h_{\phi}来预测D中的动作$ $\ \ \ \ $# 计算SOIL策略梯度,来更新我们的策略参数$\theta$ $\ \ \ \ $$\theta\leftarrow \text{PolicyOpt}(\tau_i, D’;\theta)$ $\textbf{end for}$ |
Inverse Dynamics Model
我们使用一个小的MLP网络$h_{\phi}$来估计$a_t’$,其参数为$\phi$。我们以自监督的方式来训练这个网络。每一次策略迭代中,对于当前策略$\pi_{\theta}$,我们采样一些轨迹放到Replay Buffer中,然后我们在其中均匀采样B个样本来训练这个MLP,即:
$$
a_t’=h_{\phi}(s_t,s_{t+1})
$$
损失函数我们直接就用的是$L_2$范数,因为相对来说s和a都是一些低维度的变量(高维度RL也训不出来),即:
$$
L_{inv}=||a_t’-a_t||_2
$$
SOIL策略梯度
DAPG的策略梯度如下:
$$
g_{dapg}=g+\lambda_0\lambda_1^k\sum_{(s,a)\in D}\nabla_{\theta}\log\pi_{\theta}(a|s)
$$
在SOIL中,因为我们只有s,a需要靠反向动态模型来估计。所以SOIL的策略梯度如下:
$$
g_{soil}=g+\lambda_0\lambda_1^k\sum_{(s,a’)\in D’}\nabla_{\theta}\log\pi_{\theta}(a’|s)
$$
实验结果
自此,我们整个idea部分已经讲完了。State-Only允许我们从视频中做state estimation,然后直接得到state-action pair,这样我们就不需要对视频中的高维action做估计。
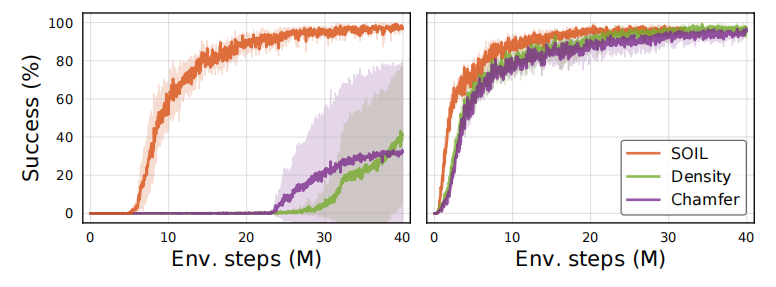
下图是对四个任务分别使用DAPG(蓝色)、SOIL(红色)和Pure RL(黄色)。注意到DAPG可以认为对于示教的每一步都有正确的$a_t$,所以可以认为是SOIL算法的上界,而Pure RL没有借助任何的示教,可以认为是SOIL算法的下界。 
State-Only Baseline的比较
本文选用了两个State-Only Baseline和SOIL比较:
- State Matching with Chamfer Distance
- Data-driven Density Estimation
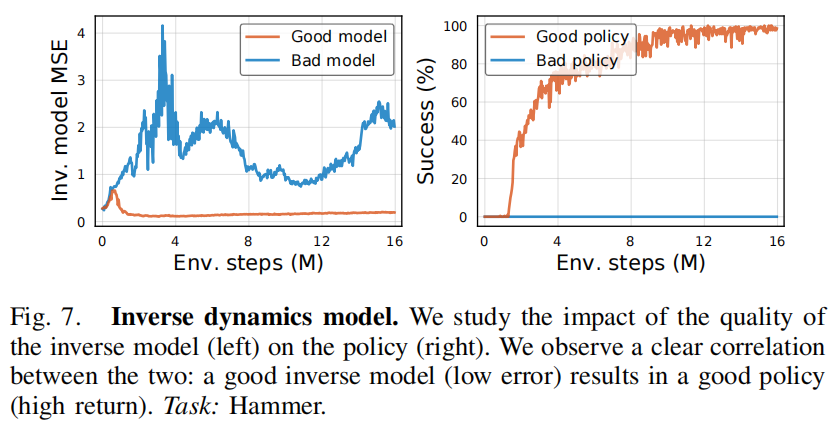
Inverse Dynamics
我们比较了一个误差大的坏的反向动态模型和好的反向动态模型对引导模仿学习的作用,可见对于示教中的action $a_t$估计更准确的模型可以更快地让策略收敛。
示教不匹配的鲁棒性实验
我们考虑在object relocation任务下,相同示教、但是实验条件不同的全局。我们考虑不同的动力学、形态和物体的情况。在这种情况下,DAPG使用原先的标注的action可能会起反作用。而我们希望证明在实验条件变化的情况下,我们的State-Only Estimation可以起到更好的作用。控制的变量有如下三个:
- Dynamics:灵巧手的质量,质量增加以后,就需要施加更大的力,因为动量增加了。
- Morphologies:原先的示教是使用灵巧手的所有手指,我们现在考虑只允许使用灵巧手部分手指的情况。
- Objects:原先是放置木块,现在我们放置一个完全不同的物体(香蕉)。
实验结果如下图所示:
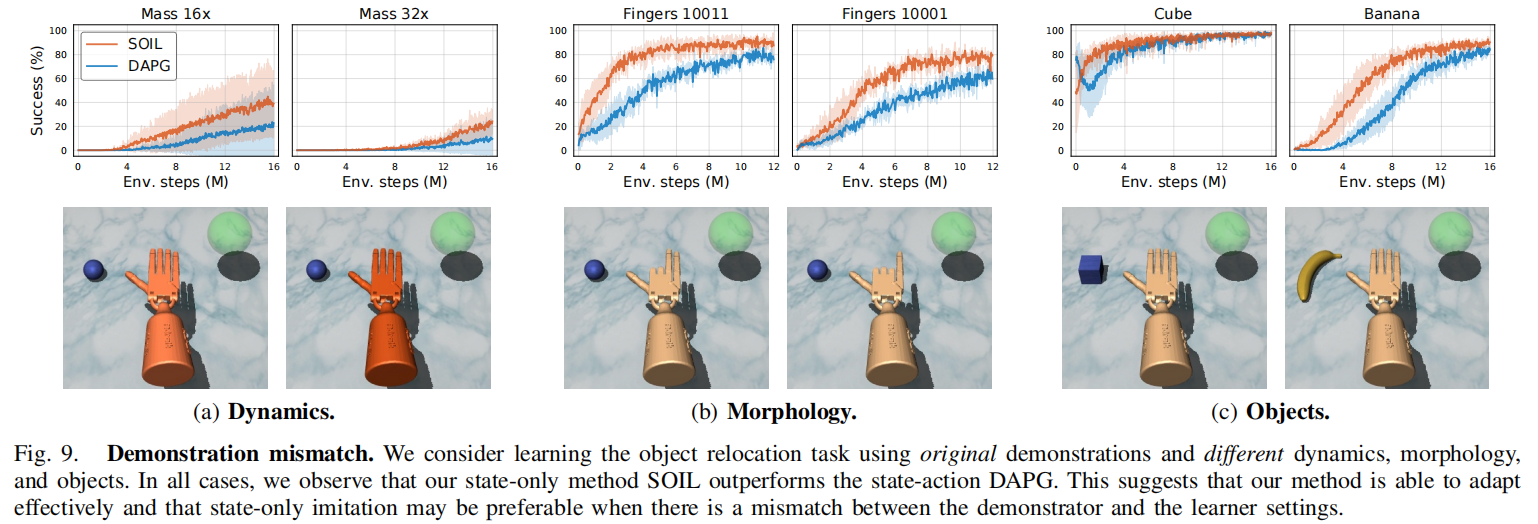
在上面这三个例子中,我们认为是GT的示教state-action pairs并没有表现得很好,这是因为在不同的场景下,要从相同的$s_t$达到$s_{t+1}$所对应的action实际上是不同的。而SOIL因为反向动态模型是针对于每个场景训练的,所以就很好地解决了这个问题。
(IROS2021)SOIL