for _ inrange(grasps_per_worker // GRASPS_PER_SCENE): # how many scene need to create # generate heap object_count = np.random.poisson(OBJECT_COUNT_LAMBDA) + 1 sim.reset(object_count) # generate the table and piled or packed objects sim.save_state()
# reconstrct point cloud using a subset of the images tsdf = create_tsdf(sim.size, 120, depth_imgs, sim.camera.intrinsic, extrinsics) pc = tsdf.get_cloud()
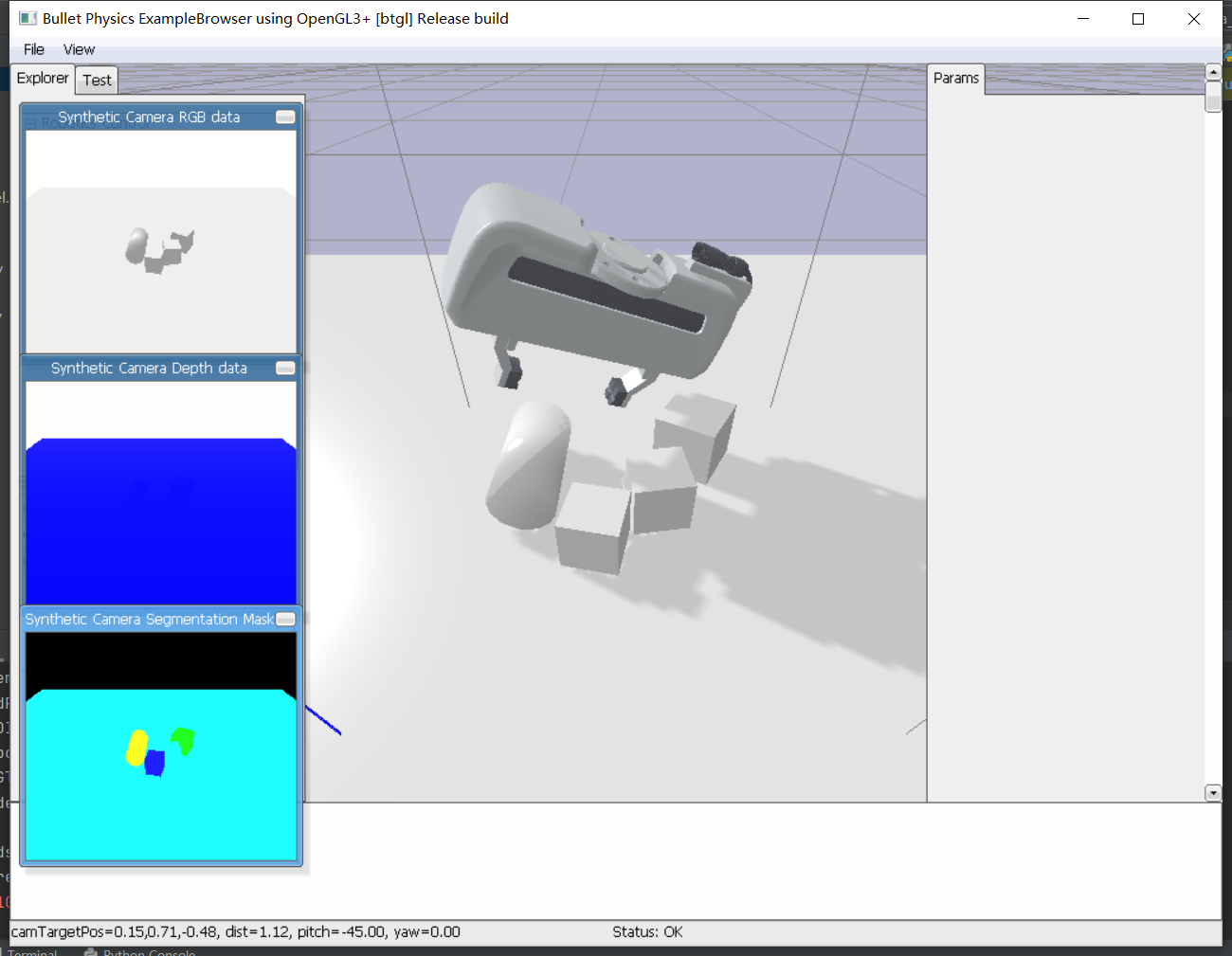
# crop surface and borders from point cloud bounding_box = o3d.geometry.AxisAlignedBoundingBox(sim.lower, sim.upper) pc = pc.crop(bounding_box) # o3d.visualization.draw_geometries([pc])
if pc.is_empty(): print("Point cloud empty, skipping scene") continue
# store the raw data scene_id = write_sensor_data(args.root, depth_imgs_side, extrinsics_side) if args.save_scene: mesh_pose_list = get_mesh_pose_list_from_world(sim.world, args.object_set) write_point_cloud(args.root, scene_id, mesh_pose_list, name="mesh_pose_list")
for _ inrange(GRASPS_PER_SCENE): # sample and evaluate a grasp point point, normal = sample_grasp_point(pc, finger_depth) grasp, label = evaluate_grasp_point(sim, point, normal)
# store the sample write_grasp(args.root, scene_id, grasp, label) pbar.update()
defsample_grasp_point(point_cloud, finger_depth, eps=0.1): # this function helps to sample grasp proposals from the raw observed point cloud points = np.asarray(point_cloud.points) normals = np.asarray(point_cloud.normals) ok = False whilenot ok: # TODO this could result in an infinite loop, though very unlikely idx = np.random.randint(len(points)) point, normal = points[idx], normals[idx] ok = normal[2] > -0.1# make sure the normal is poitning upwards grasp_depth = np.random.uniform(-eps * finger_depth, (1.0 + eps) * finger_depth) point = point + normal * grasp_depth return point, normal
defevaluate_grasp_point(sim, pos, normal, num_rotations=6): # define initial grasp frame on object surface z_axis = -normal x_axis = np.r_[1.0, 0.0, 0.0] if np.isclose(np.abs(np.dot(x_axis, z_axis)), 1.0, 1e-4): x_axis = np.r_[0.0, 1.0, 0.0] y_axis = np.cross(z_axis, x_axis) x_axis = np.cross(y_axis, z_axis) R = Rotation.from_matrix(np.vstack((x_axis, y_axis, z_axis)).T) # 在确定了pos和normal后,其实就只需要采样normal内的一个自由度的旋转角度即可,可以参考GraspNet-1Billion的叙述 # try to grasp with different yaw angles yaws = np.linspace(0.0, np.pi, num_rotations) outcomes, widths = [], [] for yaw in yaws: ori = R * Rotation.from_euler("z", yaw) sim.restore_state() candidate = Grasp(Transform(ori, pos), width=sim.gripper.max_opening_width) outcome, width = sim.execute_grasp(candidate, remove=False) outcomes.append(outcome) widths.append(width)
# detect mid-point of widest peak of successful yaw angles # TODO currently this does not properly handle periodicity successes = (np.asarray(outcomes) == Label.SUCCESS).astype(float) if np.sum(successes): peaks, properties = signal.find_peaks( x=np.r_[0, successes, 0], height=1, width=1 ) idx_of_widest_peak = peaks[np.argmax(properties["widths"])] - 1 ori = R * Rotation.from_euler("z", yaws[idx_of_widest_peak]) width = widths[idx_of_widest_peak]
for _ inrange(n_steps): T_world_tcp.translation += dist_step self.update_tcp_constraint(T_world_tcp) for _ inrange(int(dur_step / self.world.dt)): self.world.step() if abort_on_contact and self.detect_contact(): # 检测到了碰撞的情况下,根据设置直接返回或继续 return
defdetect_contact(self, threshold=5):# 通过pybullet的API做碰撞检测 if self.world.get_contacts(self.body): returnTrue else: returnFalse
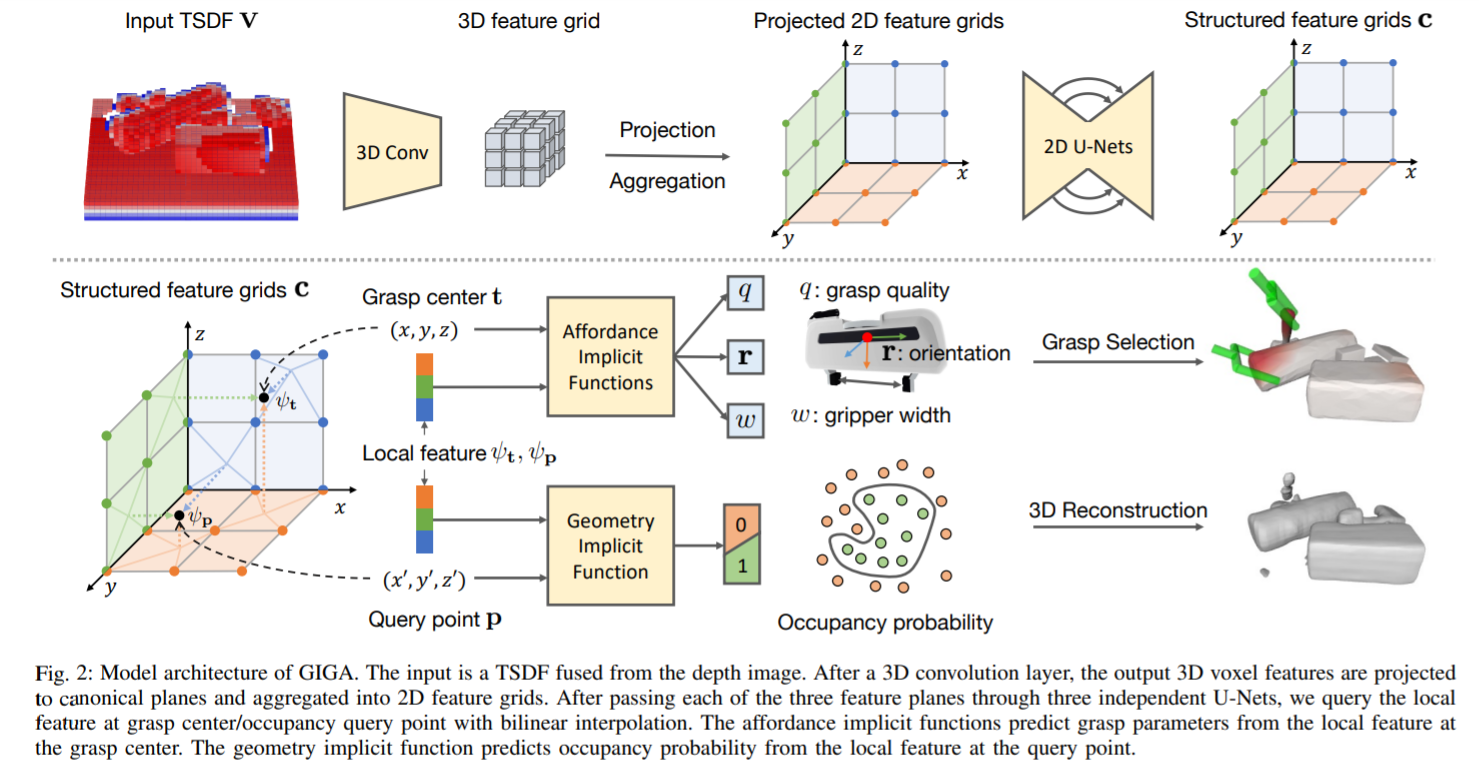
这张图就是GIGA的结构,输入的V其实可以理解为voxel representation of point cloud。经过3D卷积得到特征网格,投影其实是为了降维,因为3D CNN的计算存储开销都太大了。降维以后我们得到3个特征平面,在原文中使用的是canonical feature plane,我还以为和什么PCA相关,其实它就是往坐标轴对应的三个平面上投影了。然后在这个特征空间里,我们有待查询的抓点$t$和待查询的空间占用点$p$,我们通过对网格进行双线性插值得到对应的特征$\psi_t$和$\psi_p$,然后各自训练了一个网络去预测对应的数据。即$f_{a}(t,\psi_t)=(q,r,w)$和$f_b(p,\psi_p)=b\in[0,1]$。