最近在研究各种各样的GraspNet,组内浩树学长的GraspNet 虽然我已经用了很久,但是在方法论和具体实现上一直没有时间去研究,借着寒假的机会来集中学习一下。
其实GraspNet-1Billion包含三部分,大规模的数据集、网络和benchmark。
数据集部分 数据集包含88个日常常见的物体的3D模型。数据是从190个clutter scene中收集的,每个scene中,2个深度摄像机拍512张深度图,共97280张图片。每张图片中,我们通过计算force closure的方法稠密标注了6D grasp pose。每个场景中通常会有300万到900万个Grasp Pose。
数据收集 我原以为是仿真器里渲染的,居然真的是在现实世界中采集的,这样的话就不存在什么sim2real的问题了。两个深度相机同时拍摄场景并且合成成一个点云。摄像机所固连的机械臂的末端执行器在单位球面上找到了256个位置拍摄。地面上还放置了ArUco marker来协助摄像机标定,这样避免了计算fk所带来的误差。
数据标定 有了这97280张图以后,因为每256个位置的相对位置都是已知的,所以我们只需要标定每个的第一帧即可,即380张。但是Grasp Pose分布在一个大型的连续搜索空间中,是标不完的,手动标是巨大的工作量。因为我们的每个物体是已知的,文章中提出了一个2阶段的Grasp Pose标注方法。
首先,我们在单个物体上采样并标注Grasp Pose。为了达到这个目的,我们先把单个物体的网格模型降采样成均匀分布的Voxel space,其中的每个点称为grasp point。对于每个Grasp Point,我们从单位球找到V个均匀分布的approaching vector。然后,我们在二维网格$D\times A$上搜索(其中D是夹爪深度,而A是in-plane旋转角度)。
我们使用理论计算的方法来对每个Grasp打分,force-closure指标是很有用的:给定一个Grasp Pose、相关的Object以及摩擦系数$\mu$,它可以输出一个二分类的标签来判断这个Grasp是否可以在对应的摩擦系数下被抓起来。因为force-closure是基于物理的,所以比较鲁棒。此处我们采用24 所提到的一个改进版本,使用$\Delta\mu=0.1$作为间隔,我们逐渐从1递减到0.1,直到Grasp不再antipodal。因为具有更低摩擦系数$\mu$的成功抓取更容易成功,所以我们定义Grasp的成功率为:$s=1.1-\mu$。
对于每个scene,我们把对应单个物体的Grasp投影到clutter的场景中,此外还做了collision-check来避免非法的情况。在这两部以后,我们就对每个scene创建了稠密的抓取集合$G_{(w)}$。根据统计,数据集中正例和反例的比例为1:2。
数据集评估 对于190个场景,100个用来训练、90个用来测试。我们进一步把测试集分类为3种: 30 scenes with seen objects, 30 with unseen but similar objects and 30 for novel objects。
为了评估Grasp Pose的预测表现,之前的方法通常认为一个正确的Grasp需要满足:
但是这样的度量指标有一些问题,比如它只能评估Grasp Pose的矩阵表示方法,并且它的错误容忍度太高了,康奈尔数据集已经可以达到99%的进度了。这篇工作提出了一个在线的评估算法来评估Grasp的精度。
我们首先演示如何来分类是否一个Grasp Pose是true positive的。对于每个预测出来的Grasp Pose$\hat{P}_i$,我们首先做collision-checking,第二部就是我们通过force-closure来判断在给定不同的摩擦系数$\mu$下是否可以抓取。
对于cluttered scene,我们的Grasp预测算法会预测出多个Grasp Pose。因为对于抓取来说,我们通常是预测以后再执行的,所以我们认为true positive的比例是最重要的。因此,我们采用Precision@k作为我们的评估指标,也就是前k个抓取的精度。$AP_\mu$在摩擦系数$\mu$代表Precision@k的均值(k从1取到50)。和COCO数据集类似,我们在不同的摩擦系数$\mu$来计算$AP_\mu$。为了避免相同的Grasp Pose,在评估之前,我们对Grasp Pose来使用pose-NMS。
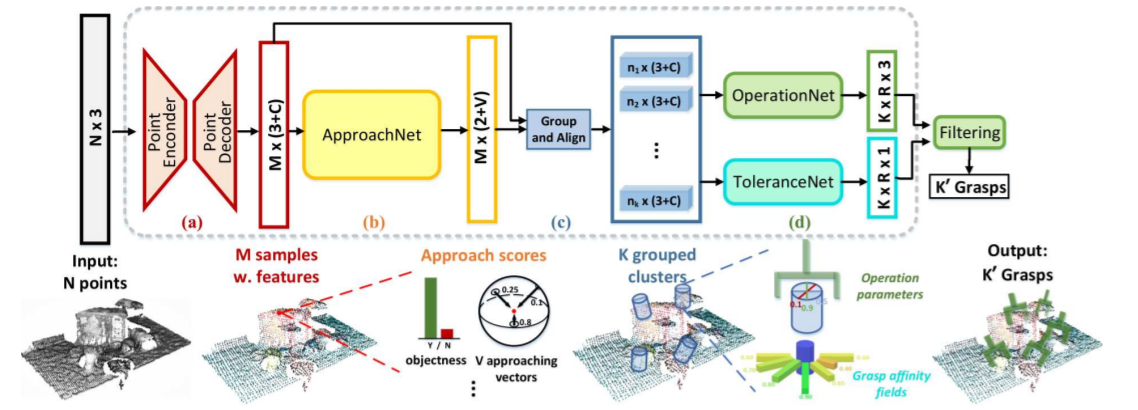
网络结构整体上我觉得和VoteNet非常接近,也是生成M个seeds。然后通过ApproachNet把Grasp的接近向量做一个多分类出来。然后我们对这M个grasp proposal做KNN聚类,聚出来K个grasp proposal。对于每个接近向量,我们继续做多分类,在$D\times A$上找到一个分数最大的夹爪渐进距离和角度。
Loss Function 对于每个候选点,我们为它分配一个二分类标签来表示它是否是可以抓取的。
对于那些不在物体上的点,我们直接认为是失败的样本。
对于在物体上的点,我们在5mm半径内寻找它是否存在至少一个graspable的GT。如果存在,对应的graspable标签即为1。
如果物体上的点附近5mm半径内没有graspable的GT,那么我们忽略掉这种情况,因为对我们的训练没有贡献。
对于每个点,我们有V个approaching vector,我们定义第i个点的第j个approaching vector为$v_{ij}$。我们然后寻找它对应的GT向量:$\hat{v}_{ij}$。类似地,我们只考虑相差在5度以内的。最终,我们的损失函数定义如下:
这个损失函数前半部分就是说,希望对每个点可以正确地二分类到graspable还是not graspable。后半部分就是说,对于每个graspable的点(满足$c_i^*==1$),它存在V个approaching vector,我们希望通过稠密的Grasp GT来让每个approaching vector都能预测出一个confidence score,也就是对应Grasp数据集创建时候,所计算出来的成功率。
Operation Network 在得到了graspable points的approaching vector之后,我们需要进一步预测in-plane rotation, approaching distance, gripper width和grasp confidence。
文章提出了一个统一的Grasp表示方式。因为approaching distance相对不那么敏感,所以分为了K个bin,对于每个给定的distance $d_k$,我们在圆柱中沿着approaching vector采样一些点。这些采样的点会转化到一个新的坐标系下,其原点是Grasp point,而z轴就是approaching vector $v_{ij}$。
Rotation和Width 在之前的文章中,证明了预测in-plane rotation时,分类比起回归有更好的效果。所以,rotation network把对齐过的点云作为输入,输出分类的分数、对每个rotation bin的归一化过的残差,以及对应的grasp width和grasp confidence。因为夹爪是对称的,所以我们只需要预测0~180度即可。目标函数如下:
Tolerance Network 现在我们已经有了一个end-to-end的网络了。本文进一步提出了Grasp Affinity Field(GAFs)的概念,它可以提升预测出来的Grasp的鲁棒性。因为合法的Grasp Pose是无限的,我们希望能够挑选出那些可以容忍更大error的鲁棒的Grasp。所以,GAFs就学习的是每个grasp对于扰动的鲁棒性。
给定一个GT的grasp pose,我们在球空间中搜索它的邻域,来找到满足grasp score > 0.5的最远的距离作为GATs。损失函数如下:
在训练过程中,网络的总的目标函数如下
Experiments GT Evaluation 为了评估预测的Grasp Pose,本文设立了一个真机实验,因为在现实中需要获取到物体的6D Pose才能做投影,把ArUco code贴在物体上。
对于训练过程,我们把in-plane rotational angle分成了12个bin、approaching distance分成了4个bin(0.01, 0.02, 0.03, 0.04)m。我们设置$M=1024$和$V=300$。我们的ApproachNet有MLP(256, 302, 302),OperationNet有MLP(128, 128, 36)和ToleranceNet有MLP(128, 64, 12)。
具体代码实现 数据集格式 数据集的官网说明如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 1. Download, unzip all the files and place them in the following structure, the train images and test images contain the 190 scenes in total. |-- graspnet |-- scenes | |-- scene_0000/ | |-- scene_0001/ | |-- ... ... | `-- scene_0189/ | | |-- models | |-- 000/ | |-- 001/ | |-- ... | `-- 087/ | | |-- dex_models(optional but strongly recommended for accelerating evaluation) | |-- 000.pkl | |-- 001.pkl | |-- ... | `-- 087.pkl | | |-- grasp_label | |-- 000_labels.npz | |-- 001_labels.npz | |-- ... | `-- 087_labels.npz | | `-- collision_label |-- scene_0000/ |-- scene_0001/ |-- ... ... `-- scene_0189/ 2. Detail structure of each scene |-- scenes |-- scene_0000 | |-- object_id_list.txt # objects' id that appear in this scene, 0-indexed | |-- rs_wrt_kn.npy # realsense camera pose with respect to kinect, shape: 256x(4x4) | |-- kinect # data of kinect camera | | |-- rgb | | | |-- 0000.png to 0255.png # 256 rgb images | | `-- depth | | | |-- 0000.png to 0255.png # 256 depth images | | `-- label | | | |-- 0000.png to 0255.png # 256 object mask images, 0 is background, 1-88 denotes each object (1-indexed), same format as YCB-Video dataset | | `-- annotations | | | |-- 0000.xml to 0255.xml # 256 object 6d pose annotation. ‘pos_in_world' and'ori_in_world' denotes position and orientation w.r.t the camera frame. | | `-- meta | | | |-- 0000.mat to 0255.mat # 256 object 6d pose annotation, same format as YCB-Video dataset for easy usage | | `-- rect | | | |-- 0000.npy to 0255.npy # 256 2D planar grasp labels | | | | | `-- camK.npy # camera intrinsic, shape: 3x3, [[f_x,0,c_x], [0,f_y,c_y], [0,0,1]] | | `-- camera_poses.npy # 256 camera poses with respect to the first frame, shape: 256x(4x4) | | `-- cam0_wrt_table.npy # first frame's camera pose with respect to the table, shape: 4x4 | | | `-- realsense | |-- same structure as kinect | | `-- scene_0001 | `-- ... ... | `-- scene_0189
我们可以看到190个场景,每个都有对应的256张RGB, depth,mask,以及每个场景中10个物体的id、Pose、以及两个摄像机的外参矩阵。
而Grasp Label的格式可以通过API官网 找到,注意到是88种物体,每一个都有一组Grasp Label。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> import numpy as np>>> l = np.load('000_labels.npz' ) >>> l.files['points' , 'offsets' , 'collision' , 'scores' ] >>> l['points' ].shape(3459 , 3 ) >>> l['offsets' ].shape(3459 , 300 , 12 , 4 , 3 ) >>> l['collision' ].shape(3459 , 300 , 12 , 4 ) >>> l['collision' ].dtypedtype('bool' ) >>> l['scores' ].shape(3459 , 300 , 12 , 4 ) >>> l['scores' ][0 ][0 ][0 ][0 ]-1.0
[‘points’] 记录了模型坐标系下的Grasp Center Point。
[‘offsets’] 记录了对应Grasp的in-plane rotation,夹爪深度和夹爪宽度。
[‘collision’] 记录了对应Grasp是否和物体模型存在碰撞。
[‘scores’] 记录了达到稳定Grasp时最小的摩擦系数。
还有一个比较重要的数据就是每个场景的collision_label,在官网中也被成为Collision Masks on Each Scene 。具体地,因为我们每个场景中维护了物体的6D Pose,我们是知道每个Grasp的位置在哪里的,我们可以预先地把我们的夹爪模型放上去做碰撞检测。如果Gripper和场景中的Model有碰撞,对于的collision_label就设置为True,我们要在训练的时候把存在碰撞的Grasp Pose的score设置为0。
1 2 3 4 5 6 7 8 9 10 >>> import numpy as np>>> c = np.load('collision_labels.npz' ) >>> c.files['arr_0' , 'arr_4' , 'arr_5' , 'arr_2' , 'arr_3' , 'arr_7' , 'arr_1' , 'arr_8' , 'arr_6' ] >>> c['arr_0' ].shape(487 , 300 , 12 , 4 ) >>> c['arr_0' ].dtypedtype('bool' ) >>> c['arr_0' ][10 ][20 ][3 ]array([ True , True , True , True ])
DataLoader 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 class GraspNetDataset (Dataset ): def __init__ (self, root, valid_obj_idxs, grasp_labels, camera='kinect' , split='train' , num_points=20000 , remove_outlier=False , remove_invisible=True , augment=False , load_label=True ): assert (num_points<=50000 ) if split == 'train' : self.sceneIds = list ( range (100 ) ) elif split == 'test' : self.sceneIds = list ( range (100 ,190 ) ) elif split == 'test_seen' : self.sceneIds = list ( range (100 ,130 ) ) elif split == 'test_similar' : self.sceneIds = list ( range (130 ,160 ) ) elif split == 'test_novel' : self.sceneIds = list ( range (160 ,190 ) ) self.sceneIds = ['scene_{}' .format (str (x).zfill(4 )) for x in self.sceneIds] def scene_list (self ): return self.scenename def __len__ (self ): return len (self.depthpath) def __getitem__ (self, index ): if self.load_label: return self.get_data_label(index) else : return self.get_data(index) def get_data (self, index, return_raw_cloud=False ): color = np.array(Image.open (self.colorpath[index]), dtype=np.float32) / 255.0 depth = np.array(Image.open (self.depthpath[index])) seg = np.array(Image.open (self.labelpath[index])) meta = scio.loadmat(self.metapath[index]) scene = self.scenename[index] intrinsic = meta['intrinsic_matrix' ] factor_depth = meta['factor_depth' ] camera = CameraInfo(1280.0 , 720.0 , intrinsic[0 ][0 ], intrinsic[1 ][1 ], intrinsic[0 ][2 ], intrinsic[1 ][2 ], factor_depth) cloud = create_point_cloud_from_depth_image(depth, camera, organized=True ) depth_mask = (depth > 0 ) seg_mask = (seg > 0 ) if self.remove_outlier: camera_poses = np.load(os.path.join(self.root, 'scenes' , scene, self.camera, 'camera_poses.npy' )) align_mat = np.load(os.path.join(self.root, 'scenes' , scene, self.camera, 'cam0_wrt_table.npy' )) trans = np.dot(align_mat, camera_poses[self.frameid[index]]) workspace_mask = get_workspace_mask(cloud, seg, trans=trans, organized=True , outlier=0.02 ) mask = (depth_mask & workspace_mask) else : mask = depth_mask cloud_masked = cloud[mask] color_masked = color[mask] seg_masked = seg[mask] if return_raw_cloud: return cloud_masked, color_masked if len (cloud_masked) >= self.num_points: idxs = np.random.choice(len (cloud_masked), self.num_points, replace=False ) else : idxs1 = np.arange(len (cloud_masked)) idxs2 = np.random.choice(len (cloud_masked), self.num_points-len (cloud_masked), replace=True ) idxs = np.concatenate([idxs1, idxs2], axis=0 ) cloud_sampled = cloud_masked[idxs] color_sampled = color_masked[idxs] ret_dict = {} ret_dict['point_clouds' ] = cloud_sampled.astype(np.float32) ret_dict['cloud_colors' ] = color_sampled.astype(np.float32) return ret_dict def get_data_label (self, index ): cloud_sampled = cloud_masked[idxs] color_sampled = color_masked[idxs] seg_sampled = seg_masked[idxs] objectness_label = seg_sampled.copy() objectness_label[objectness_label>1 ] = 1 object_poses_list = [] grasp_points_list = [] grasp_offsets_list = [] grasp_scores_list = [] grasp_tolerance_list = [] for i, obj_idx in enumerate (obj_idxs): if obj_idx not in self.valid_obj_idxs: continue if (seg_sampled == obj_idx).sum () < 50 : continue object_poses_list.append(poses[:, :, i]) points, offsets, scores, tolerance = self.grasp_labels[obj_idx] collision = self.collision_labels[scene][i] if self.remove_invisible: visible_mask = remove_invisible_grasp_points(cloud_sampled[seg_sampled==obj_idx], points, poses[:,:,i], th=0.01 ) points = points[visible_mask] offsets = offsets[visible_mask] scores = scores[visible_mask] tolerance = tolerance[visible_mask] collision = collision[visible_mask] idxs = np.random.choice(len (points), min (max (int (len (points)/4 ),300 ),len (points)), replace=False ) grasp_points_list.append(points[idxs]) grasp_offsets_list.append(offsets[idxs]) collision = collision[idxs].copy() scores = scores[idxs].copy() tolerance = tolerance[idxs].copy() scores[collision] = 0 tolerance[collision] = 0 grasp_scores_list.append(scores) grasp_tolerance_list.append(tolerance) if self.augment: cloud_sampled, object_poses_list = self.augment_data(cloud_sampled, object_poses_list) ret_dict = {} ret_dict['point_clouds' ] = cloud_sampled.astype(np.float32) ret_dict['cloud_colors' ] = color_sampled.astype(np.float32) ret_dict['objectness_label' ] = objectness_label.astype(np.int64) ret_dict['object_poses_list' ] = object_poses_list ret_dict['grasp_points_list' ] = grasp_points_list ret_dict['grasp_offsets_list' ] = grasp_offsets_list ret_dict['grasp_labels_list' ] = grasp_scores_list ret_dict['grasp_tolerance_list' ] = grasp_tolerance_list return ret_dict def augment_data (self, point_clouds, object_poses_list ): if np.random.random() > 0.5 : flip_mat = np.array([[-1 , 0 , 0 ], [ 0 , 1 , 0 ], [ 0 , 0 , 1 ]]) point_clouds = transform_point_cloud(point_clouds, flip_mat, '3x3' ) for i in range (len (object_poses_list)): object_poses_list[i] = np.dot(flip_mat, object_poses_list[i]).astype(np.float32) rot_angle = (np.random.random()*np.pi/3 ) - np.pi/6 c, s = np.cos(rot_angle), np.sin(rot_angle) rot_mat = np.array([[1 , 0 , 0 ], [0 , c,-s], [0 , s, c]]) point_clouds = transform_point_cloud(point_clouds, rot_mat, '3x3' ) for i in range (len (object_poses_list)): object_poses_list[i] = np.dot(rot_mat, object_poses_list[i]).astype(np.float32) return point_clouds, object_poses_list def collate_fn (batch ): if type (batch[0 ]).__module__ == 'numpy' : return torch.stack([torch.from_numpy(b) for b in batch], 0 ) elif isinstance (batch[0 ], container_abcs.Mapping): return {key:collate_fn([d[key] for d in batch]) for key in batch[0 ]} elif isinstance (batch[0 ], container_abcs.Sequence ): return [[torch.from_numpy(sample) for sample in b] for b in batch] raise TypeError("batch must contain tensors, dicts or lists; found {}" .format (type (batch[0 ])))
graspnet.py 我们首先来看GraspNet这个类。我们可以看到,GraspNetStage1其实就是我们的PointNet++ backbone和ApproachNet部分。而GraspNetStage2主要是OperationNet和ToleranceNet部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 class GraspNet (nn.Module ): def __init__ (self, input_feature_dim=0 , num_view=300 , num_angle=12 , num_depth=4 , cylinder_radius=0.05 , hmin=-0.02 , hmax_list=[0.01 ,0.02 ,0.03 ,0.04 ], is_training=True ): super ().__init__() self.is_training = is_training self.view_estimator = GraspNetStage1(input_feature_dim, num_view) self.grasp_generator = GraspNetStage2(num_angle, num_depth, cylinder_radius, hmin, hmax_list, is_training) def forward (self, end_points ): end_points = self.view_estimator(end_points) if self.is_training: end_points = process_grasp_labels(end_points) end_points = self.grasp_generator(end_points) return end_points
根据forward的顺序,我们先来看看GarspNetStage1的逻辑:
1 2 3 4 5 6 7 8 9 10 11 class GraspNetStage1 (nn.Module ): def __init__ (self, input_feature_dim=0 , num_view=300 ): super ().__init__() self.backbone = Pointnet2Backbone(input_feature_dim) self.vpmodule = ApproachNet(num_view, 256 ) def forward (self, end_points ): pointcloud = end_points['point_clouds' ] seed_features, seed_xyz, end_points = self.backbone(pointcloud, end_points) end_points = self.vpmodule(seed_xyz, seed_features, end_points) return end_points
其实就是走了一个Pointnet2Backbone和ApproachNet,关于PointNet不再赘述。我们来看看ApproachNet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 class ApproachNet (nn.Module ): def __init__ (self, num_view, seed_feature_dim ): """ Approach vector estimation from seed point features. Input: num_view: [int] number of views generated from each each seed point seed_feature_dim: [int] number of channels of seed point features """ super ().__init__() self.num_view = num_view self.in_dim = seed_feature_dim self.conv1 = nn.Conv1d(self.in_dim, self.in_dim, 1 ) self.conv2 = nn.Conv1d(self.in_dim, 2 +self.num_view, 1 ) self.conv3 = nn.Conv1d(2 +self.num_view, 2 +self.num_view, 1 ) self.bn1 = nn.BatchNorm1d(self.in_dim) self.bn2 = nn.BatchNorm1d(2 +self.num_view) def forward (self, seed_xyz, seed_features, end_points ): """ Forward pass. Input: seed_xyz: (B, Ns, 3), coordinates of seed points seed_features: (batch_size,feature_dim,num_seed) features of seed points end_points: [dict] Output: end_points: [dict] """ B, num_seed, _ = seed_xyz.size() features = F.relu(self.bn1(self.conv1(seed_features)), inplace=True ) features = F.relu(self.bn2(self.conv2(features)), inplace=True ) features = self.conv3(features) objectness_score = features[:, :2 , :] view_score = features[:, 2 :2 +self.num_view, :].transpose(1 ,2 ).contiguous() end_points['objectness_score' ] = objectness_score end_points['view_score' ] = view_score top_view_scores, top_view_inds = torch.max (view_score, dim=2 ) top_view_inds_ = top_view_inds.view(B, num_seed, 1 , 1 ).expand(-1 , -1 , -1 , 3 ).contiguous() template_views = generate_grasp_views(self.num_view).to(features.device) template_views = template_views.view(1 , 1 , self.num_view, 3 ).expand(B, num_seed, -1 , -1 ).contiguous() vp_xyz = torch.gather(template_views, 2 , top_view_inds_).squeeze(2 ) vp_xyz_ = vp_xyz.view(-1 , 3 ) batch_angle = torch.zeros(vp_xyz_.size(0 ), dtype=vp_xyz.dtype, device=vp_xyz.device) vp_rot = batch_viewpoint_params_to_matrix(-vp_xyz_, batch_angle).view(B, num_seed, 3 , 3 ) end_points['grasp_top_view_inds' ] = top_view_inds end_points['grasp_top_view_score' ] = top_view_scores end_points['grasp_top_view_xyz' ] = vp_xyz end_points['grasp_top_view_rot' ] = vp_rot return end_points
注意到在GraspNet的forward过程中,我们的end_points需要经过process_grasp_labels这个函数。我们先来看看这个函数在做什么,它主要做了几件事情:
把物体坐标系下的Grasp投射到标准场景坐标系下,并且聚类到最近的场景系下的标准模板向量(V个approaching vector)
根据聚类结果对(Ns, V, A, D, 3)的第2维度V重排顺序,使得第二维满足相同的顺序,即不同物体的Grasp可以合成一个tensor:(Np’, V, A, D, 3),其中满足$N_P’=\sum N_P$。
对物体的原先标签Grasp Label做转换,原先的意义是达到稳定抓取的最小摩擦系数,转换成Score时需要满足摩擦系数越大的Grasp的成功率越小,所以其中做了一个归一化的倒数处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 def process_grasp_labels (end_points ): """ 根据场景中的点和场景中物体的6D Pose处理grasp labels""" clouds = end_points['input_xyz' ] seed_xyzs = end_points['fp2_xyz' ] batch_size, num_samples, _ = seed_xyzs.size() batch_grasp_points = [] batch_grasp_views = [] batch_grasp_views_rot = [] batch_grasp_labels = [] batch_grasp_offsets = [] batch_grasp_tolerance = [] for i in range (batch_size): seed_xyz = seed_xyzs[i] poses = end_points['object_poses_list' ][i] grasp_points_merged = [] grasp_views_merged = [] grasp_views_rot_merged = [] grasp_labels_merged = [] grasp_offsets_merged = [] grasp_tolerance_merged = [] for obj_idx, pose in enumerate (poses): grasp_points = end_points['grasp_points_list' ][i][obj_idx] grasp_labels = end_points['grasp_labels_list' ][i][obj_idx] grasp_offsets = end_points['grasp_offsets_list' ][i][obj_idx] grasp_tolerance = end_points['grasp_tolerance_list' ][i][obj_idx] _, V, A, D = grasp_labels.size() num_grasp_points = grasp_points.size(0 ) grasp_views = generate_grasp_views(V).to(pose.device) grasp_points_trans = transform_point_cloud(grasp_points, pose, '3x4' )、 grasp_views_trans = transform_point_cloud(grasp_views, pose[:3 ,:3 ], '3x3' ) angles = torch.zeros(grasp_views.size(0 ), dtype=grasp_views.dtype, device=grasp_views.device) grasp_views_rot = batch_viewpoint_params_to_matrix(-grasp_views, angles) grasp_views_rot_trans = torch.matmul(pose[:3 ,:3 ], grasp_views_rot) grasp_views_ = grasp_views.transpose(0 , 1 ).contiguous().unsqueeze(0 ) grasp_views_trans_ = grasp_views_trans.transpose(0 , 1 ).contiguous().unsqueeze(0 ) view_inds = knn(grasp_views_trans_, grasp_views_, k=1 ).squeeze() - 1 grasp_views_trans = torch.index_select(grasp_views_trans, 0 , view_inds) grasp_views_trans = grasp_views_trans.unsqueeze(0 ).expand(num_grasp_points, -1 , -1 ) grasp_views_rot_trans = torch.index_select(grasp_views_rot_trans, 0 , view_inds) grasp_views_rot_trans = grasp_views_rot_trans.unsqueeze(0 ).expand(num_grasp_points, -1 , -1 , -1 ) grasp_labels = torch.index_select(grasp_labels, 1 , view_inds) grasp_offsets = torch.index_select(grasp_offsets, 1 , view_inds) grasp_tolerance = torch.index_select(grasp_tolerance, 1 , view_inds) grasp_points_merged.append(grasp_points_trans) grasp_views_merged.append(grasp_views_trans) grasp_views_rot_merged.append(grasp_views_rot_trans) grasp_labels_merged.append(grasp_labels) grasp_offsets_merged.append(grasp_offsets) grasp_tolerance_merged.append(grasp_tolerance) grasp_points_merged = torch.cat(grasp_points_merged, dim=0 ) grasp_views_merged = torch.cat(grasp_views_merged, dim=0 ) grasp_views_rot_merged = torch.cat(grasp_views_rot_merged, dim=0 ) grasp_labels_merged = torch.cat(grasp_labels_merged, dim=0 ) grasp_offsets_merged = torch.cat(grasp_offsets_merged, dim=0 ) grasp_tolerance_merged = torch.cat(grasp_tolerance_merged, dim=0 ) seed_xyz_ = seed_xyz.transpose(0 , 1 ).contiguous().unsqueeze(0 ) grasp_points_merged_ = grasp_points_merged.transpose(0 , 1 ).contiguous().unsqueeze(0 ) nn_inds = knn(grasp_points_merged_, seed_xyz_, k=1 ).squeeze() - 1 grasp_points_merged = torch.index_select(grasp_points_merged, 0 , nn_inds) grasp_views_merged = torch.index_select(grasp_views_merged, 0 , nn_inds) grasp_views_rot_merged = torch.index_select(grasp_views_rot_merged, 0 , nn_inds) grasp_labels_merged = torch.index_select(grasp_labels_merged, 0 , nn_inds) grasp_offsets_merged = torch.index_select(grasp_offsets_merged, 0 , nn_inds) grasp_tolerance_merged = torch.index_select(grasp_tolerance_merged, 0 , nn_inds) batch_grasp_points.append(grasp_points_merged) batch_grasp_views.append(grasp_views_merged) batch_grasp_views_rot.append(grasp_views_rot_merged) batch_grasp_labels.append(grasp_labels_merged) batch_grasp_offsets.append(grasp_offsets_merged) batch_grasp_tolerance.append(grasp_tolerance_merged) batch_grasp_points = torch.stack(batch_grasp_points, 0 ) batch_grasp_views = torch.stack(batch_grasp_views, 0 ) batch_grasp_views_rot = torch.stack(batch_grasp_views_rot, 0 ) batch_grasp_labels = torch.stack(batch_grasp_labels, 0 ) batch_grasp_offsets = torch.stack(batch_grasp_offsets, 0 ) batch_grasp_tolerance = torch.stack(batch_grasp_tolerance, 0 ) batch_grasp_widths = batch_grasp_offsets[:,:,:,:,:,2 ] label_mask = (batch_grasp_labels > 0 ) & (batch_grasp_widths <= GRASP_MAX_WIDTH) u_max = batch_grasp_labels.max () batch_grasp_labels[label_mask] = torch.log(u_max / batch_grasp_labels[label_mask]) batch_grasp_labels[~label_mask] = 0 batch_grasp_view_scores, _ = batch_grasp_labels.view(batch_size, num_samples, V, A*D).max (dim=-1 ) end_points['batch_grasp_point' ] = batch_grasp_points end_points['batch_grasp_view' ] = batch_grasp_views end_points['batch_grasp_view_rot' ] = batch_grasp_views_rot end_points['batch_grasp_label' ] = batch_grasp_labels end_points['batch_grasp_offset' ] = batch_grasp_offsets end_points['batch_grasp_tolerance' ] = batch_grasp_tolerance end_points['batch_grasp_view_label' ] = batch_grasp_view_scores.float () return end_points
GraspNetStage2的结构如下,它主要包含三个模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 class GraspNetStage2 (nn.Module ): def __init__ (self, num_angle=12 , num_depth=4 , cylinder_radius=0.05 , hmin=-0.02 , hmax_list=[0.01 ,0.02 ,0.03 ,0.04 ], is_training=True ): super ().__init__() self.num_angle = num_angle self.num_depth = num_depth self.is_training = is_training self.crop = CloudCrop(nsample=64 , seed_feature_dim=3 , cylinder_radius=cylinder_radius, hmin=hmin, hmax_list=hmax_list) self.operation = OperationNet(num_angle, num_depth) self.tolerance = ToleranceNet(num_angle, num_depth) def forward (self, end_points ): pointcloud = end_points['input_xyz' ] if self.is_training: grasp_top_views_rot, _, _, _, end_points = match_grasp_view_and_label(end_points) seed_xyz = end_points['batch_grasp_point' ] else : grasp_top_views_rot = end_points['grasp_top_view_rot' ] seed_xyz = end_points['fp2_xyz' ] vp_features = self.crop(seed_xyz, pointcloud, grasp_top_views_rot) end_points = self.operation(vp_features, end_points) end_points = self.tolerance(vp_features, end_points) return end_points def match_grasp_view_and_label (end_points ): top_view_inds = end_points['grasp_top_view_inds' ] template_views_rot = end_points['batch_grasp_view_rot' ] grasp_labels = end_points['batch_grasp_label' ] grasp_offsets = end_points['batch_grasp_offset' ] grasp_tolerance = end_points['batch_grasp_tolerance' ] B, Ns, V, A, D = grasp_labels.size() top_view_inds_ = top_view_inds.view(B, Ns, 1 , 1 , 1 ).expand(-1 , -1 , -1 , 3 , 3 ) top_template_views_rot = torch.gather(template_views_rot, 2 , top_view_inds_).squeeze(2 ) top_view_inds_ = top_view_inds.view(B, Ns, 1 , 1 , 1 ).expand(-1 , -1 , -1 , A, D) top_view_grasp_labels = torch.gather(grasp_labels, 2 , top_view_inds_).squeeze(2 ) top_view_grasp_tolerance = torch.gather(grasp_tolerance, 2 , top_view_inds_).squeeze(2 ) top_view_inds_ = top_view_inds.view(B, Ns, 1 , 1 , 1 , 1 ).expand(-1 , -1 , -1 , A, D, 3 ) top_view_grasp_offsets = torch.gather(grasp_offsets, 2 , top_view_inds_).squeeze(2 ) end_points['batch_grasp_view_rot' ] = top_template_views_rot end_points['batch_grasp_label' ] = top_view_grasp_labels end_points['batch_grasp_offset' ] = top_view_grasp_offsets end_points['batch_grasp_tolerance' ] = top_view_grasp_tolerance return top_template_views_rot, top_view_grasp_labels, top_view_grasp_offsets, top_view_grasp_tolerance, end_points
接下来CloudCrop模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class CloudCrop (nn.Module ): """ Cylinder group and align for grasp configure estimation. Return a list of grouped points with different cropping depths. Input: nsample: [int] sample number in a group seed_feature_dim: [int] number of channels of grouped points cylinder_radius: [float] radius of the cylinder space hmin: [float] height of the bottom surface hmax_list: [list of float] list of heights of the upper surface """ def __init__ (self, nsample, seed_feature_dim, cylinder_radius=0.05 , hmin=-0.02 , hmax_list=[0.01 ,0.02 ,0.03 ,0.04 ] ): super ().__init__() self.nsample = nsample self.in_dim = seed_feature_dim self.cylinder_radius = cylinder_radius mlps = [self.in_dim, 64 , 128 , 256 ] self.groupers = [] for hmax in hmax_list: self.groupers.append(CylinderQueryAndGroup(cylinder_radius, hmin, hmax, nsample, use_xyz=True )) self.mlps = pt_utils.SharedMLP(mlps, bn=True ) def forward (self, seed_xyz, pointcloud, vp_rot ): """ Forward pass. Input: seed_xyz: (B, Ns, 3), coordinates of seed points pointcloud: (B, Ns, 3), the points to be cropped vp_rot: (B, Ns, 3, 3), rotation matrices generated from approach vectors Output: vp_features: (B, num_features, Ns,num_depth), features of grouped points in different depths """ B, num_seed, _, _ = vp_rot.size() num_depth = len (self.groupers) grouped_features = [] for grouper in self.groupers: grouped_features.append(grouper(pointcloud, seed_xyz, vp_rot)) grouped_features = torch.stack(grouped_features, dim=3 ) grouped_features = grouped_features.view(B, -1 , num_seed*num_depth, self.nsample) vp_features = self.mlps(grouped_features) vp_features = F.max_pool2d(vp_features, kernel_size=[1 , vp_features.size(3 )]) vp_features = vp_features.view(B, -1 , num_seed, num_depth) return vp_features
在此之中,用到了一个CylinderQueryAndGroup模块,我们进一步往下探索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 class CylinderQueryAndGroup (nn.Module ): r""" Groups with a cylinder query of radius and height Parameters --------- radius : float32 Radius of cylinder hmin, hmax: float32 endpoints of cylinder height in x-rotation axis nsample : int32 Maximum number of features to gather in the ball """ def __init__ (self, radius, hmin, hmax, nsample, use_xyz=True , ret_grouped_xyz=False , normalize_xyz=False , rotate_xyz=True , sample_uniformly=False , ret_unique_cnt=False ): super (CylinderQueryAndGroup, self).__init__() self.radius, self.nsample, self.hmin, self.hmax, = radius, nsample, hmin, hmax self.use_xyz = use_xyz self.ret_grouped_xyz = ret_grouped_xyz self.normalize_xyz = normalize_xyz self.rotate_xyz = rotate_xyz self.sample_uniformly = sample_uniformly self.ret_unique_cnt = ret_unique_cnt if self.ret_unique_cnt: assert (self.sample_uniformly) def forward (self, xyz, new_xyz, rot, features=None ): """ Parameters ---------- xyz : 点云坐标 (B, N, 3) new_xyz : 抓点中心 (B, npoint, 3) rot : 抓点的旋转矩阵 (B, npoint, 3, 3) features : torch.Tensor Descriptors of the features (B, C, N) Returns ------- new_features : torch.Tensor (B, 3 + C, npoint, nsample) tensor """ B, npoint, _ = new_xyz.size() idx = cylinder_query(self.radius, self.hmin, self.hmax, self.nsample, xyz, new_xyz, rot.view(B, npoint, 9 )) if self.sample_uniformly: unique_cnt = torch.zeros((idx.shape[0 ], idx.shape[1 ])) for i_batch in range (idx.shape[0 ]): for i_region in range (idx.shape[1 ]): unique_ind = torch.unique(idx[i_batch, i_region, :]) num_unique = unique_ind.shape[0 ] unique_cnt[i_batch, i_region] = num_unique sample_ind = torch.randint(0 , num_unique, (self.nsample - num_unique,),dtype=torch.long) all_ind = torch.cat((unique_ind, unique_ind[sample_ind])) idx[i_batch, i_region, :] = all_ind xyz_trans = xyz.transpose(1 , 2 ).contiguous() grouped_xyz = grouping_operation(xyz_trans, idx) grouped_xyz -= new_xyz.transpose(1 , 2 ).unsqueeze(-1 ) if self.normalize_xyz: grouped_xyz /= self.radius if self.rotate_xyz: grouped_xyz_ = grouped_xyz.permute(0 , 2 , 3 , 1 ).contiguous() grouped_xyz_ = torch.matmul(grouped_xyz_, rot) grouped_xyz = grouped_xyz_.permute(0 , 3 , 1 , 2 ).contiguous() if features is not None : grouped_features = grouping_operation(features, idx) if self.use_xyz: new_features = torch.cat( [grouped_xyz, grouped_features], dim=1 ) else : new_features = grouped_features else : assert (self.use_xyz), "Cannot have not features and not use xyz as a feature!" new_features = grouped_xyz ret = [new_features] if self.ret_grouped_xyz: ret.append(grouped_xyz) if self.ret_unique_cnt: ret.append(unique_cnt) if len (ret) == 1 : return ret[0 ] else : return tuple (ret)
为了理解其中cylinder_query的作用,我们看到其CUDA实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 __global__ void query_ball_point_kernel (int b, int n, int m, float radius, int nsample, const float *__restrict__ new_xyz, const float *__restrict__ xyz, int *__restrict__ idx) int batch_index = blockIdx.x; xyz += batch_index * n * 3 ; new_xyz += batch_index * m * 3 ; idx += m * nsample * batch_index; int index = threadIdx.x; int stride = blockDim.x; float radius2 = radius * radius; for (int j = index; j < m; j += stride) { float new_x = new_xyz[j * 3 + 0 ]; float new_y = new_xyz[j * 3 + 1 ]; float new_z = new_xyz[j * 3 + 2 ]; for (int k = 0 , cnt = 0 ; k < n && cnt < nsample; ++k) { float x = xyz[k * 3 + 0 ]; float y = xyz[k * 3 + 1 ]; float z = xyz[k * 3 + 2 ]; float d2 = (new_x - x) * (new_x - x) + (new_y - y) * (new_y - y) + (new_z - z) * (new_z - z); if (d2 < radius2) { if (cnt == 0 ) { for (int l = 0 ; l < nsample; ++l) { idx[j * nsample + l] = k; } } idx[j * nsample + cnt] = k; ++cnt; } } } } __global__ void query_cylinder_point_kernel (int b, int n , int m, float radius, float hmin, float hmax, int nsample, const float *__restrict__ new_xyz, const float *__restrict__ xyz, const float *__restrict__ rot, int *__restrict__ idx) int batch_index = blockIdx.x; xyz += batch_index * n * 3 ; new_xyz += batch_index * m * 3 ; rot += batch_index * m * 9 ; idx += m * nsample * batch_index; int index = threadIdx.x; int stride = blockDim.x; float radius2 = radius * radius; for (int j = index; j < m; j += stride) { float new_x = new_xyz[j * 3 + 0 ]; float new_y = new_xyz[j * 3 + 1 ]; float new_z = new_xyz[j * 3 + 2 ]; float r0 = rot[j * 9 + 0 ]; float r1 = rot[j * 9 + 1 ]; float r2 = rot[j * 9 + 2 ]; float r3 = rot[j * 9 + 3 ]; float r4 = rot[j * 9 + 4 ]; float r5 = rot[j * 9 + 5 ]; float r6 = rot[j * 9 + 6 ]; float r7 = rot[j * 9 + 7 ]; float r8 = rot[j * 9 + 8 ]; for (int k = 0 , cnt = 0 ; k < n && cnt < nsample; ++k) { float x = xyz[k * 3 + 0 ] - new_x; float y = xyz[k * 3 + 1 ] - new_y; float z = xyz[k * 3 + 2 ] - new_z; float x_rot = r0 * x + r3 * y + r6 * z; float y_rot = r1 * x + r4 * y + r7 * z; float z_rot = r2 * x + r5 * y + r8 * z; float d2 = y_rot * y_rot + z_rot * z_rot; if (d2 < radius2 && x_rot > hmin && x_rot < hmax) { if (cnt == 0 ) { for (int l = 0 ; l < nsample; ++l) { idx[j * nsample + l] = k; } } idx[j * nsample + cnt] = k; ++cnt; } } } }
所以上述CylinderQuery的意义就是在圆柱范围内对点做聚类。
接下来是OperationNet和ToleranceNet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 class OperationNet (nn.Module ): """ Grasp configure estimation. Input: num_angle: [int] number of in-plane rotation angle classes the value of the i-th class --> i*PI/num_angle (i=0,...,num_angle-1) num_depth: [int] number of gripper depth classes """ def __init__ (self, num_angle, num_depth ): super ().__init__() self.num_angle = num_angle self.num_depth = num_depth self.conv1 = nn.Conv1d(256 , 128 , 1 ) self.conv2 = nn.Conv1d(128 , 128 , 1 ) self.conv3 = nn.Conv1d(128 , 3 *num_angle, 1 ) self.bn1 = nn.BatchNorm1d(128 ) self.bn2 = nn.BatchNorm1d(128 ) def forward (self, vp_features, end_points ): """ Forward pass. Input: vp_features: (B, mlps[-1], Ns, D) features of grouped points in different depths end_points: [dict] Output: end_points: [dict] """ B, _, num_seed, num_depth = vp_features.size() vp_features = vp_features.view(B, -1 , num_seed*num_depth) vp_features = F.relu(self.bn1(self.conv1(vp_features)), inplace=True ) vp_features = F.relu(self.bn2(self.conv2(vp_features)), inplace=True ) vp_features = self.conv3(vp_features) vp_features = vp_features.view(B, -1 , num_seed, num_depth) end_points['grasp_score_pred' ] = vp_features[:, 0 :self.num_angle] end_points['grasp_angle_cls_pred' ] = vp_features[:, self.num_angle:2 *self.num_angle] end_points['grasp_width_pred' ] = vp_features[:, 2 *self.num_angle:3 *self.num_angle] return end_points class ToleranceNet (nn.Module ): """ Grasp tolerance prediction. Input: num_angle: [int] number of in-plane rotation angle classes the value of the i-th class --> i*PI/num_angle (i=0,...,num_angle-1) num_depth: [int] number of gripper depth classes """ def __init__ (self, num_angle, num_depth ): super ().__init__() self.conv1 = nn.Conv1d(256 , 128 , 1 ) self.conv2 = nn.Conv1d(128 , 128 , 1 ) self.conv3 = nn.Conv1d(128 , num_angle, 1 ) self.bn1 = nn.BatchNorm1d(128 ) self.bn2 = nn.BatchNorm1d(128 ) def forward (self, vp_features, end_points ): """ Forward pass. Input: vp_features: [torch.FloatTensor, (batch_size,num_seed,3)] features of grouped points in different depths end_points: [dict] Output: end_points: [dict] """ B, _, num_seed, num_depth = vp_features.size() vp_features = vp_features.view(B, -1 , num_seed*num_depth) vp_features = F.relu(self.bn1(self.conv1(vp_features)), inplace=True ) vp_features = F.relu(self.bn2(self.conv2(vp_features)), inplace=True ) vp_features = self.conv3(vp_features) vp_features = vp_features.view(B, -1 , num_seed, num_depth) end_points['grasp_tolerance_pred' ] = vp_features return end_points
到这里为止,GraspNet的前向传播过程全部结束。我们接下来需要通过pred_decode对预测的end_points字典解码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 def pred_decode (end_points ): batch_size = len (end_points['point_clouds' ]) grasp_preds = [] for i in range (batch_size): objectness_score = end_points['objectness_score' ][i].float () grasp_score = end_points['grasp_score_pred' ][i].float () grasp_angle_class_score = end_points['grasp_angle_cls_pred' ][i] grasp_width = 1.2 * end_points['grasp_width_pred' ][i] grasp_width = torch.clamp(grasp_width, min =0 , max =GRASP_MAX_WIDTH) grasp_tolerance = end_points['grasp_tolerance_pred' ][i] grasp_center = end_points['fp2_xyz' ][i].float () approaching = -end_points['grasp_top_view_xyz' ][i].float () grasp_angle_class = torch.argmax(grasp_angle_class_score, 0 ) grasp_angle = grasp_angle_class.float () / 12 * np.pi grasp_angle_class_ = grasp_angle_class.unsqueeze(0 ) grasp_score = torch.gather(grasp_score, 0 , grasp_angle_class_).squeeze(0 ) grasp_width = torch.gather(grasp_width, 0 , grasp_angle_class_).squeeze(0 ) grasp_tolerance = torch.gather(grasp_tolerance, 0 , grasp_angle_class_).squeeze(0 ) grasp_depth_class = torch.argmax(grasp_score, 1 , keepdims=True ) grasp_depth = (grasp_depth_class.float ()+1 ) * 0.01 grasp_score = torch.gather(grasp_score, 1 , grasp_depth_class) grasp_angle = torch.gather(grasp_angle, 1 , grasp_depth_class) grasp_width = torch.gather(grasp_width, 1 , grasp_depth_class) grasp_tolerance = torch.gather(grasp_tolerance, 1 , grasp_depth_class) objectness_pred = torch.argmax(objectness_score, 0 ) objectness_mask = (objectness_pred==1 ) grasp_score = grasp_score[objectness_mask] grasp_width = grasp_width[objectness_mask] grasp_depth = grasp_depth[objectness_mask] approaching = approaching[objectness_mask] grasp_angle = grasp_angle[objectness_mask] grasp_center = grasp_center[objectness_mask] grasp_tolerance = grasp_tolerance[objectness_mask] grasp_score = grasp_score * grasp_tolerance / GRASP_MAX_TOLERANCE Ns = grasp_angle.size(0 ) approaching_ = approaching.view(Ns, 3 ) grasp_angle_ = grasp_angle.view(Ns) rotation_matrix = batch_viewpoint_params_to_matrix(approaching_, grasp_angle_) rotation_matrix = rotation_matrix.view(Ns, 9 ) grasp_height = 0.02 * torch.ones_like(grasp_score) obj_ids = -1 * torch.ones_like(grasp_score) grasp_preds.append(torch.cat([grasp_score, grasp_width, grasp_height, grasp_depth, rotation_matrix, grasp_center, obj_ids], axis=-1 )) return grasp_preds
loss.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 def get_loss (end_points ): objectness_loss, end_points = compute_objectness_loss(end_points) view_loss, end_points = compute_view_loss(end_points) grasp_loss, end_points = compute_grasp_loss(end_points) loss = objectness_loss + view_loss + 0.2 * grasp_loss end_points['loss/overall_loss' ] = loss return loss, end_points def compute_objectness_loss (end_points ): criterion = nn.CrossEntropyLoss(reduction='mean' ) objectness_score = end_points['objectness_score' ] objectness_label = end_points['objectness_label' ] fp2_inds = end_points['fp2_inds' ].long() objectness_label = torch.gather(objectness_label, 1 , fp2_inds) loss = criterion(objectness_score, objectness_label) end_points['loss/stage1_objectness_loss' ] = loss objectness_pred = torch.argmax(objectness_score, 1 ) end_points['stage1_objectness_acc' ] = (objectness_pred == objectness_label.long()).float ().mean() end_points['stage1_objectness_prec' ] = (objectness_pred == objectness_label.long())[objectness_pred == 1 ].float ().mean() end_points['stage1_objectness_recall' ] = (objectness_pred == objectness_label.long())[objectness_label == 1 ].float ().mean() return loss, end_points def compute_view_loss (end_points ): criterion = nn.MSELoss(reduction='none' ) view_score = end_points['view_score' ] view_label = end_points['batch_grasp_view_label' ] objectness_label = end_points['objectness_label' ] fp2_inds = end_points['fp2_inds' ].long() V = view_label.size(2 ) objectness_label = torch.gather(objectness_label, 1 , fp2_inds) objectness_mask = (objectness_label > 0 ) objectness_mask = objectness_mask.unsqueeze(-1 ).repeat(1 , 1 , V) pos_view_pred_mask = ((view_score >= THRESH_GOOD) & objectness_mask) loss = criterion(view_score, view_label) loss = loss[objectness_mask].mean() end_points['loss/stage1_view_loss' ] = loss end_points['stage1_pos_view_pred_count' ] = pos_view_pred_mask.long().sum () return loss, end_points def compute_grasp_loss (end_points, use_template_in_training=True ): top_view_inds = end_points['grasp_top_view_inds' ] vp_rot = end_points['grasp_top_view_rot' ] objectness_label = end_points['objectness_label' ] fp2_inds = end_points['fp2_inds' ].long() objectness_mask = torch.gather(objectness_label, 1 , fp2_inds).bool () batch_grasp_label = end_points['batch_grasp_label' ] batch_grasp_offset = end_points['batch_grasp_offset' ] batch_grasp_tolerance = end_points['batch_grasp_tolerance' ] B, Ns, A, D = batch_grasp_label.size() top_view_grasp_angles = batch_grasp_offset[:, :, :, :, 0 ] top_view_grasp_depths = batch_grasp_offset[:, :, :, :, 1 ] top_view_grasp_widths = batch_grasp_offset[:, :, :, :, 2 ] target_labels_inds = torch.argmax(batch_grasp_label, dim=2 , keepdim=True ) target_labels = torch.gather(batch_grasp_label, 2 , target_labels_inds).squeeze(2 ) target_angles = torch.gather(top_view_grasp_angles, 2 , target_labels_inds).squeeze(2 ) target_depths = torch.gather(top_view_grasp_depths, 2 , target_labels_inds).squeeze(2 ) target_widths = torch.gather(top_view_grasp_widths, 2 , target_labels_inds).squeeze(2 ) target_tolerance = torch.gather(batch_grasp_tolerance, 2 , target_labels_inds).squeeze(2 ) graspable_mask = (target_labels > THRESH_BAD) objectness_mask = objectness_mask.unsqueeze(-1 ).expand_as(graspable_mask) loss_mask = (objectness_mask & graspable_mask).float () target_labels_inds_ = target_labels_inds.transpose(1 , 2 ) grasp_score = torch.gather(end_points['grasp_score_pred' ], 1 , target_labels_inds_).squeeze(1 ) grasp_score_loss = huber_loss(grasp_score - target_labels, delta=1.0 ) grasp_score_loss = torch.sum (grasp_score_loss * loss_mask) / (loss_mask.sum () + 1e-6 ) end_points['loss/stage2_grasp_score_loss' ] = grasp_score_loss target_angles_cls = target_labels_inds.squeeze(2 ) criterion_grasp_angle_class = nn.CrossEntropyLoss(reduction='none' ) grasp_angle_class_score = end_points['grasp_angle_cls_pred' ] grasp_angle_class_loss = criterion_grasp_angle_class(grasp_angle_class_score, target_angles_cls) grasp_angle_class_loss = torch.sum (grasp_angle_class_loss * loss_mask) / (loss_mask.sum () + 1e-6 ) end_points['loss/stage2_grasp_angle_class_loss' ] = grasp_angle_class_loss grasp_angle_class_pred = torch.argmax(grasp_angle_class_score, 1 ) end_points['stage2_grasp_angle_class_acc/0_degree' ] = (grasp_angle_class_pred==target_angles_cls)[loss_mask.bool ()].float ().mean() acc_mask_15 = ((torch.abs (grasp_angle_class_pred-target_angles_cls) <= 1 ) | (torch.abs (grasp_angle_class_pred-target_angles_cls) >= A - 1 )) end_points['stage2_grasp_angle_class_acc/15_degree' ] = acc_mask_15[loss_mask.bool ()].float ().mean() acc_mask_30 = ((torch.abs (grasp_angle_class_pred-target_angles_cls) <= 2 ) | (torch.abs (grasp_angle_class_pred-target_angles_cls) >= A - 2 )) end_points['stage2_grasp_angle_class_acc/30_degree' ] = acc_mask_30[loss_mask.bool ()].float ().mean() grasp_width_pred = torch.gather(end_points['grasp_width_pred' ], 1 , target_labels_inds_).squeeze(1 ) grasp_width_loss = huber_loss((grasp_width_pred-target_widths)/GRASP_MAX_WIDTH, delta=1 ) grasp_width_loss = torch.sum (grasp_width_loss * loss_mask) / (loss_mask.sum () + 1e-6 ) end_points['loss/stage2_grasp_width_loss' ] = grasp_width_loss grasp_tolerance_pred = torch.gather(end_points['grasp_tolerance_pred' ], 1 , target_labels_inds_).squeeze(1 ) grasp_tolerance_loss = huber_loss((grasp_tolerance_pred-target_tolerance)/GRASP_MAX_TOLERANCE, delta=1 ) grasp_tolerance_loss = torch.sum (grasp_tolerance_loss * loss_mask) / (loss_mask.sum () + 1e-6 ) end_points['loss/stage2_grasp_tolerance_loss' ] = grasp_tolerance_loss grasp_loss = grasp_score_loss + grasp_angle_class_loss\ + grasp_width_loss + grasp_tolerance_loss return grasp_loss, end_points def huber_loss (error, delta=1.0 ): """ Args: error: Torch tensor (d1,d2,...,dk) Returns: loss: Torch tensor (d1,d2,...,dk) x = error = pred - gt or dist(pred,gt) 0.5 * |x|^2 if |x|<=d 0.5 * d^2 + d * (|x|-d) if |x|>d Author: Charles R. Qi Ref: https://github.com/charlesq34/frustum-pointnets/blob/master/models/model_util.py """ abs_error = torch.abs (error) quadratic = torch.clamp(abs_error, max =delta) linear = (abs_error - quadratic) loss = 0.5 * quadratic**2 + delta * linear return loss
附言 和浩树学长聊了一下,他很明确地指出这其实是一个多分类任务。并且因为论文中提到了使用离散的Bin来代替回归出一个向量的idea,我就继续请教了一下这样做的原因。因为这一点其实在VoteNet中尝试预测物体的6D pose的时候,也是有体现的。他认为回归在方法论上就不太对,因为正常的情况下Valid Approach Vector / Operations 应当是一个分布,而不是回归出来的一个值。多分类对于每个离散的bin预测出一个score,在我的理解下,就是用细粒度的均匀分布去拟合这个我们所希望预测的分布,这样训练效果就会好。听罢,感叹自己科研的路上还有很多路要走…因为各种各样的论文只会告诉你它的优点是什么,真正的硬伤都不会写在论文里。而要把握领域前沿动向,并且做出正确的选择,那就必须要在这种抽象层面上建构出自己稳定的理论体系, 但是我觉得我自己还差了很多这一块的知识积累。真是道阻且长啊。好在,我在努力开发出很多未来可以使用的方法论、视野、论文积累、代码积累等,希望可以在这条路上继续努力!