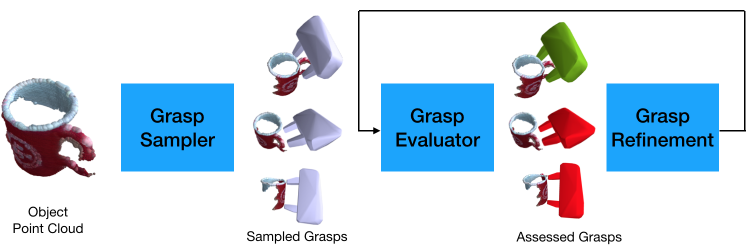
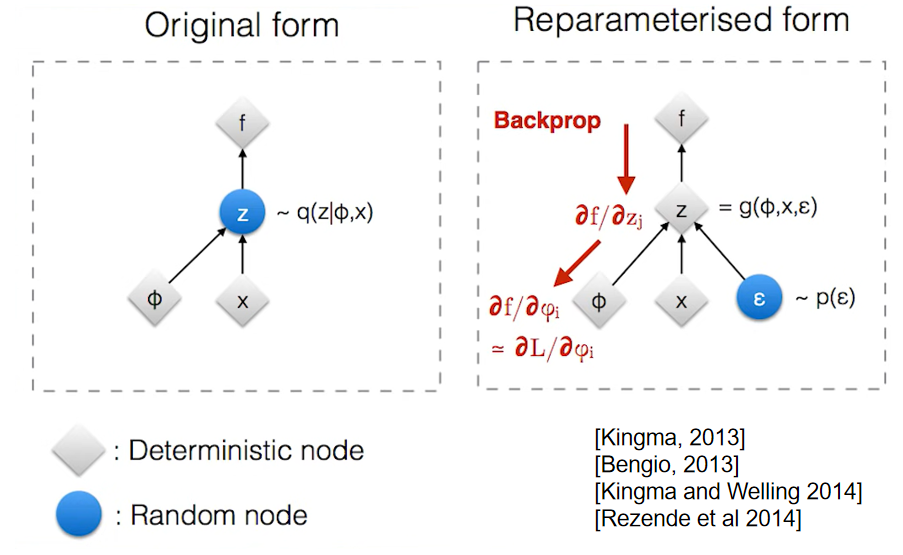
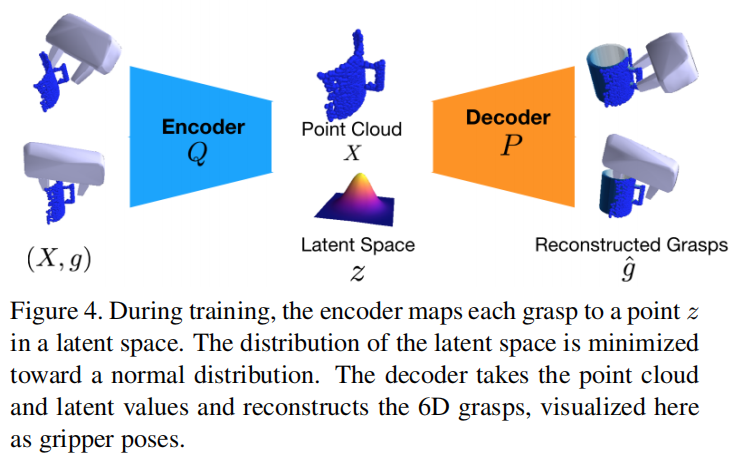
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
| class GraspEstimator:
"""
Includes the code used for running the inference.
"""
def __init__(self, grasp_sampler_opt, grasp_evaluator_opt, opt):
self.grasp_sampler_opt = grasp_sampler_opt
self.grasp_evaluator_opt = grasp_evaluator_opt
self.opt = opt
self.target_pc_size = opt.target_pc_size
self.num_refine_steps = opt.refine_steps
self.refine_method = opt.refinement_method
self.threshold = opt.threshold
self.batch_size = opt.batch_size
self.generate_dense_grasps = opt.generate_dense_grasps
if self.generate_dense_grasps:
self.num_grasps_per_dim = opt.num_grasp_samples
self.num_grasp_samples = opt.num_grasp_samples * opt.num_grasp_samples
else:
self.num_grasp_samples = opt.num_grasp_samples
self.choose_fn = opt.choose_fn
self.choose_fns = {
"all":
None,
"better_than_threshold":
utils.choose_grasps_better_than_threshold,
"better_than_threshold_in_sequence":
utils.choose_grasps_better_than_threshold_in_sequence,
}
self.device = torch.device("cuda:0")
self.grasp_evaluator = create_model(grasp_evaluator_opt)
self.grasp_sampler = create_model(grasp_sampler_opt)
def keep_inliers(self, grasps, confidences, z, pc, inlier_indices_list):
for i, inlier_indices in enumerate(inlier_indices_list):
grasps[i] = grasps[i][inlier_indices]
confidences[i] = confidences[i][inlier_indices]
z[i] = z[i][inlier_indices]
pc[i] = pc[i][inlier_indices]
def generate_and_refine_grasps(self, pc):
pc_list, pc_mean = self.prepare_pc(pc)
grasps_list, confidence_list, z_list = self.generate_grasps(pc_list)
inlier_indices = utils.get_inlier_grasp_indices(grasps_list,
torch.zeros(1, 3).to(
self.device),
threshold=1.0,
device=self.device)
self.keep_inliers(grasps_list, confidence_list, z_list, pc_list, inlier_indices)
improved_eulers, improved_ts, improved_success = [], [], []
for pc, grasps in zip(pc_list, grasps_list):
out = self.refine_grasps(pc, grasps, self.refine_method,
self.num_refine_steps)
improved_eulers.append(out[0])
improved_ts.append(out[1])
improved_success.append(out[2])
improved_eulers = np.hstack(improved_eulers)
improved_ts = np.hstack(improved_ts)
improved_success = np.hstack(improved_success)
if self.choose_fn is "all":
selection_mask = np.ones(improved_success.shape, dtype=np.float32)
else:
selection_mask = self.choose_fns[self.choose_fn](improved_eulers,
improved_ts,
improved_success,
self.threshold)
grasps = utils.rot_and_trans_to_grasps(improved_eulers, improved_ts,
selection_mask)
utils.denormalize_grasps(grasps, pc_mean)
refine_indexes, sample_indexes = np.where(selection_mask)
success_prob = improved_success[refine_indexes,
sample_indexes].tolist()
return grasps, success_prob
def prepare_pc(self, pc):
if pc.shape[0] > self.target_pc_size:
pc = utils.regularize_pc_point_count(pc, self.target_pc_size)
pc_mean = np.mean(pc, 0)
pc -= np.expand_dims(pc_mean, 0)
pc = np.tile(pc, (self.num_grasp_samples, 1, 1))
pc = torch.from_numpy(pc).float().to(self.device)
pcs = []
pcs = utils.partition_array_into_subarrays(pc, self.batch_size)
return pcs, pc_mean
def generate_grasps(self, pcs):
all_grasps = []
all_confidence = []
all_z = []
if self.generate_dense_grasps:
latent_samples = self.grasp_sampler.net.module.generate_dense_latents(
self.num_grasps_per_dim)
latent_samples = utils.partition_array_into_subarrays(
latent_samples, self.batch_size)
for latent_sample, pc in zip(latent_samples, pcs):
grasps, confidence, z = self.grasp_sampler.generate_grasps(
pc, latent_sample)
all_grasps.append(grasps)
all_confidence.append(confidence)
all_z.append(z)
else:
for pc in pcs:
grasps, confidence, z = self.grasp_sampler.generate_grasps(pc)
all_grasps.append(grasps)
all_confidence.append(confidence)
all_z.append(z)
return all_grasps, all_confidence, all_z
def refine_grasps(self, pc, grasps, refine_method, num_refine_steps=10):
grasp_eulers, grasp_translations = utils.convert_qt_to_rt(grasps)
if refine_method == "gradient":
improve_fun = self.improve_grasps_gradient_based
grasp_eulers = torch.autograd.Variable(grasp_eulers.to(
self.device),requires_grad=True)
grasp_translations = torch.autograd.Variable(grasp_translations.to(
self.device),requires_grad=True)
else:
improve_fun = self.improve_grasps_sampling_based
improved_success = []
improved_eulers = []
improved_ts = []
improved_eulers.append(grasp_eulers.cpu().data.numpy())
improved_ts.append(grasp_translations.cpu().data.numpy())
last_success = None
for i in range(num_refine_steps):
success_prob, last_success = improve_fun(pc, grasp_eulers,
grasp_translations,
last_success)
improved_success.append(success_prob.cpu().data.numpy())
improved_eulers.append(grasp_eulers.cpu().data.numpy())
improved_ts.append(grasp_translations.cpu().data.numpy())
grasp_pcs = utils.control_points_from_rot_and_trans(
grasp_eulers, grasp_translations, self.device)
improved_success.append(
self.grasp_evaluator.evaluate_grasps(
pc, grasp_pcs).squeeze().cpu().data.numpy())
return np.asarray(improved_eulers), np.asarray(
improved_ts), np.asarray(improved_success)
def improve_grasps_gradient_based(self, pcs, grasp_eulers, grasp_trans, last_success):
grasp_pcs = utils.control_points_from_rot_and_trans(
grasp_eulers, grasp_trans, self.device)
success = self.grasp_evaluator.evaluate_grasps(pcs, grasp_pcs)
success.squeeze().backward(
torch.ones(success.shape[0]).to(self.device))
delta_t = grasp_trans.grad
norm_t = torch.norm(delta_t, p=2, dim=-1).to(self.device)
alpha = torch.min(0.01 / norm_t, torch.tensor(1.0).to(self.device))
grasp_trans.data += grasp_trans.grad * alpha[:, None]
temp = grasp_eulers.clone()
grasp_eulers.data += grasp_eulers.grad * alpha[:, None]
return success.squeeze(), None
def improve_grasps_sampling_based(self, pcs, grasp_eulers, grasp_trans, last_success=None):
with torch.no_grad():
if last_success is None:
grasp_pcs = utils.control_points_from_rot_and_trans(
grasp_eulers, grasp_trans, self.device)
last_success = self.grasp_evaluator.evaluate_grasps(
pcs, grasp_pcs)
delta_t = 2 * (torch.rand(grasp_trans.shape).to(self.device) - 0.5)
delta_t *= 0.02
delta_euler_angles = (torch.rand(grasp_eulers.shape).to(self.device) - 0.5) * 2
perturbed_translation = grasp_trans + delta_t
perturbed_euler_angles = grasp_eulers + delta_euler_angles
grasp_pcs = utils.control_points_from_rot_and_trans(
perturbed_euler_angles, perturbed_translation, self.device)
perturbed_success = self.grasp_evaluator.evaluate_grasps(pcs, grasp_pcs)
ratio = perturbed_success / torch.max(last_success, torch.tensor(0.0001).to(self.device))
mask = torch.rand(ratio.shape).to(self.device) <= ratio
next_success = last_success
ind = torch.where(mask)[0]
next_success[ind] = perturbed_success[ind]
grasp_trans[ind].data = perturbed_translation.data[ind]
grasp_eulers[ind].data = perturbed_euler_angles.data[ind]
return last_success.squeeze(), next_success
|