最近一门机器学习的课有一个阅读论文的作业,我选了老本行votenet,不过发现自己一些实现细节还是不过关。借着这个机会再从pointnet开始梳理一下思路并且解读一下源码。讲解视频
PointNet PointNet一定是3D pointcloud perception的里程碑,保留了大道至简的美感的同时,给出了严格的证明。是从每个角度都应该称赞的作品。
正如原文所说,又是空间中的n个点的集合有如下特性:
无序性(输出应当与输入的n个点的排序无关)
点和其邻居之间是有一些依赖关系的,我们设计的网络需要能够从邻居点中提取出局部特征
旋转和位移不变性(不过pointnet和pointnet++对旋转的处理都不是很好)
所以pointnet使用了max-pooling层来作为对称函数解决点云无序性的问题。
PointNet的证明 我们令$\chi={S:S\subseteq[0,1]^m\text{and}|S|=n}$,此处的S就是我们的input,即一个欧式空间中的点集实例。此处做了归一化处理,所以它是模长恒定的m维向量。而$\chi$自然就是欧式空间中的点集的集合。我们希望拟合一个定义在集合上的连续函数$f:\chi\rightarrow\mathbb{R}$,注意此处的$\mathbb{R}$是指实数空间,而不是实数。
因为这个函数是连续函数,所以在点集$S,S’\in\chi$上有如下性质:
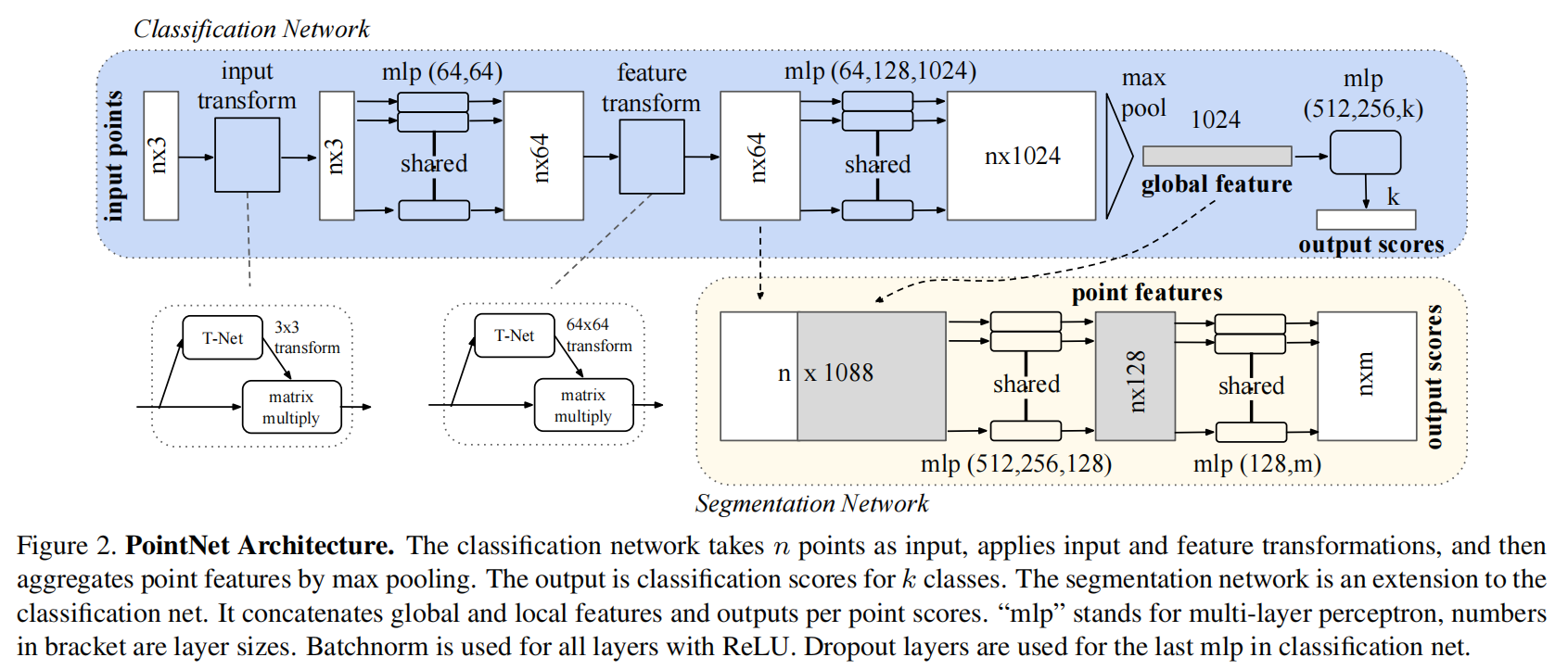
对于PointNet来说,它得到的拟合出来的函数的形式是:$\gamma(\mathop{MAX}_{x_i\in S}{h(x_i)})$。其中,我们令$S={x_1,x_2,…,x_n}$,其中$x_i\in R^N$,比如说我们单纯的空间位置的话,那就是$N=3$,而$h(x_i)$其实就是对这n个点做shared-MLP,得到的结果做一个maxpooling出一个$1\times1024$维的global feature。然后$\gamma$其实就是最后处理global feature的MLP。
我们需要证明的就是
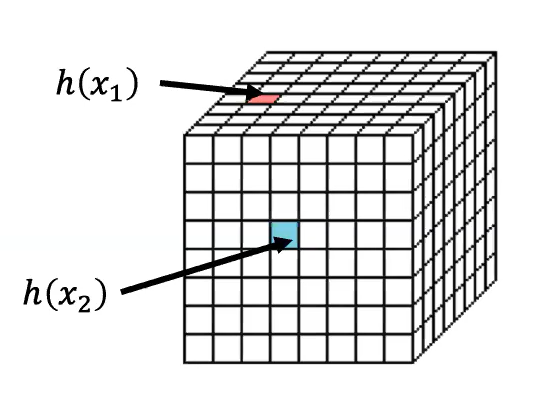
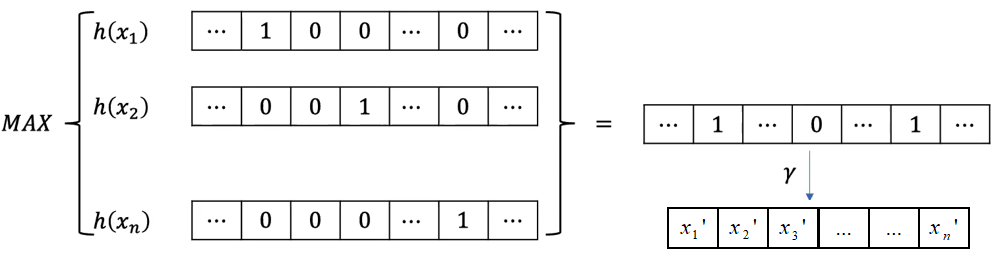
相对直观的分析 我们可以简单地认为$h(·)$就是把$x_i$映射到空间网格中的一个格子里,我们记这个空间网格的大小为$M\times M\times M$。那么因为点只会映射到一个网格中,我们可以得到$h(x_i)$就是一个大小为$1\times M^3$的向量,并且只有一个值为1,其余值为0。
而MAX函数我们可以认为是使用空间网格来重建我们的输入点云,我们可以令这个网格足够密集(M足够大),使得每个网格至多包含一个原先的点,这样就等于我们做完max-pooling后,得到了一个$1\times M^3$的向量,其中有n个点为1,其余为0。
因为网格的密度可以足够大,所以我们可以使用网格模型以任意精度去近似我们原先的点云集合$S$。接下来的$\gamma$其实就是对这个新的表示形式的$1\times M^3$向量(global feature)去做一个MLP。因为MLP可以近似任意函数,那它自然也能近似$f$函数,得证。本证明过程参考了深蓝学院的点云课程 。
论文中的纯数学分析 参考CSDN 。知乎 。
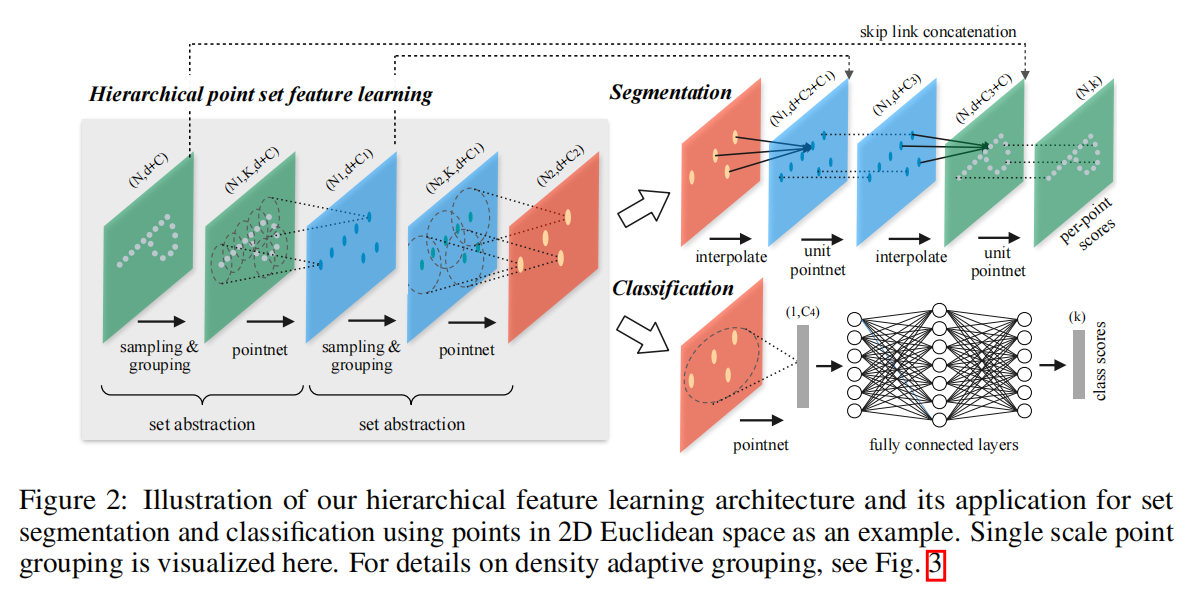
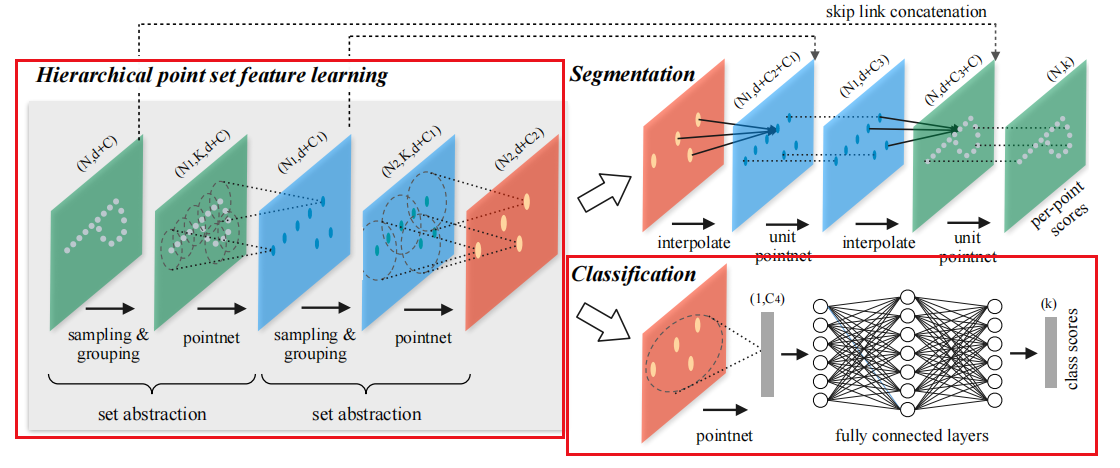
PointNet++ PointNet只使用一个max-pooling层来整合全局信息,而PointNet++使用层级结构来逐层提取特征,并且不断地从层级中抽象出更大的局部区域。在PointNet++中,主要是通过set abstraction layer来实现的,它包含了sampling layer(最远点采样), grouping layer和PointNet layer。
Sampling Layer 其实这一部分就是一个最远点采样的工作。也就是输入的维度是$B\times N \times(C+D)$,通常情况下$C=3$,而$D$就是特征维度,并且我们已知当前层需要采样到$\text{npoints}$个点。那么其实就是$B\times N \times (C+D)\rightarrow B\times\text{npoints}\times(C+D)$。
Grouping Layer 这个层的目标是找到每个点的邻居,其实就是从半径为$r$的球中找到至多$\text{nsample}$个元素。
PointNet Layer 这个其实就是拿原先的PointNet来提取特征。
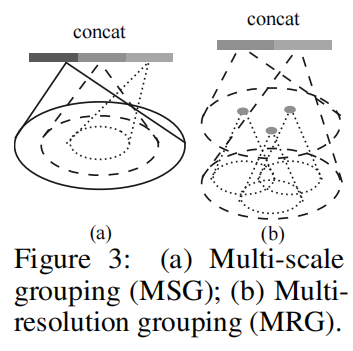
Set Abstraction Layer的MSG优化
因为原先的set abstraction layer是在固定的一个半径上去做的,感受野是固定大小。而MSG就是在多个不同的半径上去提取特征,最后组合在一起。
Point Feature Propagation 在set abstraction layer中,原先的点集被降采样了。然而在点分割任务中,我们需要对每个点获取到一个点的种类标签,所以我们希望得到原先所有点的一个特征。一个方法就是在set abstraction layer中,我们永远采样所有的点作为中心点,但是这会导致计算消耗非常大,另一个方法就是使用point feature propagation。
在feature propagation layer中,它的输入是$N_i\times(d+C)$,而它的输出的$N_{i-1}\times(d+C)$,注意到其中的$N_i$就是在每层的set abstraction layer中的大小。所以其实这就是一个Decoder,并且在每一层Decode得到了全局特征后,再拼上了原先set abstraction layer的局部特征。
代码 接下来我们尝试来理解PointNet++的源码,PointNet++提供了三种任务的代码:classification、part segmentation和semantic segmentation,而set abstraction layer分为了SSG(single-scale grouping)和MSG(multi-scale grouping)。通常有纯Python版本的Pytorch实现 和带有Cuda实现功能函数的Pytorch实现 ,因为最原先开源的版本是Tensorflow版本,这两个Pytorch版本在变量命名上都借鉴了原先版本的命名,但是这和论文中的参数命名是一个都对不上。并且个别出出现了破坏软件抽象规则的地方,如在PointNetSetAbstractionMsg中调用了类似于sample_and_group的结构但并没有复用代码,亦或者sample_and_group_all其实可以规约到sample_and_group,但是又重新写了一个函数等一系列问题。所以总体代码看起来比较痛苦,不过当我们彻底搞清楚代码以后,我们就可以把PoineNet++当做开箱即用的东西,再也不管它的底层实现了。
sample_and_group的实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def sample_and_group (npoint, radius, nsample, xyz, features, returnfps=False ): """ Input: npoint: N_{i+1} radius: 查询半径 nsample: 考察至多几个邻域中的点 xyz: input points position data, [B, N, 3] features: input points feature data, [B, N, C] Return: new_xyz: sampled points position data, [B, npoint, nsample, 3] new_FEATURES: sampled points feature data, [B, npoint, nsample, 3+D] """ B, N, d = xyz.shape fps_idx = farthest_point_sample(xyz, npoint) new_xyz = index_points(xyz, fps_idx) idx = query_ball_point(radius, nsample, xyz, new_xyz) grouped_xyz = index_points(xyz, idx) grouped_xyz_norm = grouped_xyz - new_xyz.view(B, npoint, 1 , d) if features is not None : grouped_features = index_points(features, idx) new_features = torch.cat([grouped_xyz_norm, grouped_features], dim=-1 ) else : new_features = grouped_xyz_norm if returnfps: return new_xyz, new_features, grouped_xyz, fps_idx else : return new_xyz, new_features
query_ball_point的实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def query_ball_point (radius, K, xyz, new_xyz ): """ Input: radius: local region radius nsample: max sample number in local region,注意这个邻居是要在原先的N_i个点中找的。 xyz: all points, [B, N_i, 3] new_xyz: query points, [B, N_{i+1}, 3] Return: group_idx: grouped points index, [B, N_{i+1}, K] """ device = xyz.device B, N, C = xyz.shape _, npoint, _ = new_xyz.shape group_idx = torch.arange(N, dtype=torch.long).to(device).view(1 , 1 , N).repeat([B, npoint, 1 ]) sqrdists = square_distance(new_xyz, xyz) group_idx[sqrdists > radius ** 2 ] = N group_idx = group_idx.sort(dim=-1 )[0 ][:, :, :K] group_first = group_idx[:, :, 0 ].view(B, S, 1 ).repeat([1 , 1 , K]) mask = group_idx == N group_idx[mask] = group_first[mask] return group_idx
Classificaction Task 这一部分其实就是论文中的这个结构:
我们注意到在实现中有$N_1=512,N_2=128$,$d=3$是点云的欧式空间坐标,如果点云输入有法向量数据,那么$C=3$,否则$C=0$。并且中间层有$C_1=128,C_2=256,C_4=1024,k=\text{num_class}$,在数据集modelnet40下,$k=\text{num_class}=40$。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class get_model (nn.Module ): def __init__ (self,num_class,normal_channel=True ): super (get_model, self).__init__() in_channel = 6 if normal_channel else 3 self.normal_channel = normal_channel self.sa1 = PointNetSetAbstraction(npoint=512 , radius=0.2 , K=32 , in_channel=in_channel, mlp=[64 , 64 , 128 ], group_all=False ) self.sa2 = PointNetSetAbstraction(npoint=128 , radius=0.4 , K=64 , in_channel=128 + 3 , mlp=[128 , 128 , 256 ], group_all=False ) self.sa3 = PointNetSetAbstraction(npoint=None , radius=None , K=None , in_channel=256 + 3 , mlp=[256 , 512 , 1024 ], group_all=True ) self.fc1 = nn.Linear(1024 , 512 ) self.bn1 = nn.BatchNorm1d(512 ) self.drop1 = nn.Dropout(0.4 ) self.fc2 = nn.Linear(512 , 256 ) self.bn2 = nn.BatchNorm1d(256 ) self.drop2 = nn.Dropout(0.4 ) self.fc3 = nn.Linear(256 , num_class) def forward (self, xyz ): B, _, _ = xyz.shape if self.normal_channel: norm = xyz[:, 3 :, :] xyz = xyz[:, :3 , :] else : norm = None l1_xyz, l1_features = self.sa1(xyz, norm) l2_xyz, l2_features = self.sa2(l1_xyz, l1_features) l3_xyz, l3_features = self.sa3(l2_xyz, l2_features) x = l3_features.view(B, 1024 ) x = self.drop1(F.relu(self.bn1(self.fc1(x)))) x = self.drop2(F.relu(self.bn2(self.fc2(x)))) x = self.fc3(x) x = F.log_softmax(x, -1 ) return x, l3_features
接下来其实就是看set abstraction模块了,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class PointNetSetAbstraction (nn.Module ): def __init__ (self, npoint, radius, K, in_channel, mlp, group_all ): super (PointNetSetAbstraction, self).__init__() self.npoint = npoint self.radius = radius self.K = K self.mlp_convs = nn.ModuleList() self.mlp_bns = nn.ModuleList() last_channel = in_channel for out_channel in mlp: self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1 )) self.mlp_bns.append(nn.BatchNorm2d(out_channel)) last_channel = out_channel self.group_all = group_all def forward (self, xyz, points ): """ Input: xyz: input points position data, [B, 3, N_i] features: input points feature data, [B, C_i, N_i] Return: new_xyz: sampled points position data, [B, 3, N_{i+1}] new_features: sample points feature data, [B, C_{i+1}, N_{i+1}] """ xyz = xyz.permute(0 , 2 , 1 ) if features is not None : features = features.permute(0 , 2 , 1 ) if self.group_all: new_xyz, new_features = sample_and_group_all(xyz, features) else : new_xyz, new_features = sample_and_group(self.npoint, self.radius, self.K, xyz, features) new_features_concat = new_points.permute(0 , 3 , 2 , 1 ) for i, conv in enumerate (self.mlp_convs): bn = self.mlp_bns[i] new_features_concat = F.relu(bn(conv(new_features_concat))) new_features_concat = torch.max (new_features_concat, 2 )[0 ] new_xyz = new_xyz.permute(0 , 2 , 1 ) return new_xyz, new_features_concat
对于set abstraction layer来说,它的输入是$B\times N_{i} \times (3+C_i)$,而它的输出是$B\times N_{i+1}\times(3+C_{i+1})$。
理论上这样我们的分类任务已经可以完成了,这也是SSG(single-scale grouping)的情况。我们需要再看一下论文所提出的MSG的set abstraction module是如何实现的。
我们可以看到models里总体架构没有变,唯一有区别的就是两个sa层变为了SA_MSG。
1 2 3 self.sa1 = PointNetSetAbstractionMsg(npoint=512 , radius_list=[0.1 , 0.2 , 0.4 ], K_list=[16 , 32 , 128 ], in_channel=in_channel, mlp_list=[[32 , 32 , 64 ], [64 , 64 , 128 ], [64 , 96 , 128 ]]) self.sa2 = PointNetSetAbstractionMsg(npoint=128 , radius_list=[0.2 , 0.4 , 0.8 ], K_list=[32 , 64 , 128 ], in_channel=320 , mlp_list=[[64 , 64 , 128 ], [128 , 128 , 256 ], [128 , 128 , 256 ]]) self.sa3 = PointNetSetAbstraction(npoint=None , radius=None , K=None , in_channel=640 + 3 , mlp=[256 , 512 , 1024 ], group_all=True )
其实我们只要搞明白上述的in_channel各自是怎么来的。以sa2的in_channel为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class PointNetSetAbstractionMsg (nn.Module ): def __init__ (self, npoint, radius_list, K_list, in_channel, mlp_list ): super (PointNetSetAbstractionMsg, self).__init__() self.npoint = npoint self.radius_list = radius_list self.nsample_list = nsample_list self.conv_blocks = nn.ModuleList() self.bn_blocks = nn.ModuleList() for i in range (len (mlp_list)): convs = nn.ModuleList() bns = nn.ModuleList() last_channel = in_channel + 3 for out_channel in mlp_list[i]: convs.append(nn.Conv2d(last_channel, out_channel, 1 )) bns.append(nn.BatchNorm2d(out_channel)) last_channel = out_channel self.conv_blocks.append(convs) self.bn_blocks.append(bns) def forward (self, xyz, points ): """ Input: xyz: input points position data, [B, 3, N_i] points: input points data, [B, C_i, N_i] Return: new_xyz: sampled points position data, [B, 3, N_{i+1}] new_points_concat: sample points feature data, [B, C_{i+1}, N_{i+1}] """ xyz = xyz.permute(0 , 2 , 1 ) if points is not None : points = points.permute(0 , 2 , 1 ) B, N, C = xyz.shape new_xyz = index_points(xyz, farthest_point_sample(xyz, self.npoint)) new_points_list = [] for j, radius in enumerate (self.radius_list): K = self.nsample_list[j] group_idx = query_ball_point(radius, K, xyz, new_xyz) grouped_xyz = index_points(xyz, group_idx) grouped_xyz -= new_xyz.view(B, S, 1 , C) if points is not None : grouped_points = index_points(points, group_idx) grouped_points = torch.cat([grouped_points, grouped_xyz], dim=-1 ) else : grouped_points = grouped_xyz grouped_points = grouped_points.permute(0 , 3 , 2 , 1 ) for k in range (len (self.conv_blocks[j])): conv = self.conv_blocks[j][k] bn = self.bn_blocks[j][k] grouped_points = F.relu(bn(conv(grouped_points))) new_points = torch.max (grouped_points, 2 )[0 ] new_points_list.append(new_points) new_xyz = new_xyz.permute(0 , 2 , 1 ) new_points_concat = torch.cat(new_points_list, dim=1 ) print ("new_points_concat.size = " , new_points_concat) return new_xyz, new_points_concat
Q:PointNet++梯度是如何回传的???
A:PointNet++ fps实际上并没有参与梯度计算和反向传播。
可以理解成是PointNet++将点云进行不同规模的fps降采样,事先将这些数据准备好,再送到网络中去训练。
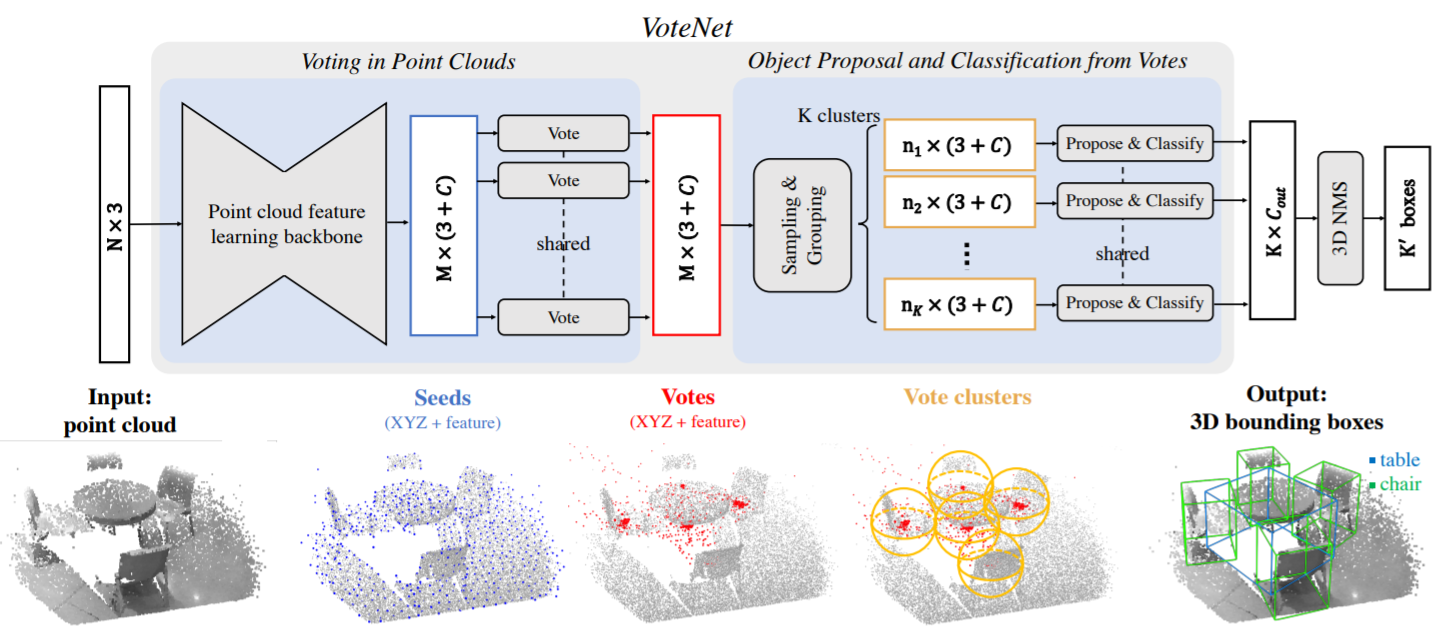
VoteNet VoteNet是基于end-to-end的3D目标检测网络,它基于3D的深度点云网络和霍夫投票。
可以从讲解视频 和PPT 获得相关内容。
votenet.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 class VoteNet (nn.Module ): r""" A deep neural network for 3D object detection with end-to-end optimizable hough voting. Parameters ---------- num_class: int Number of semantics classes to predict over -- size of softmax classifier num_heading_bin: int num_size_cluster: int input_feature_dim: (default: 0) Input dim in the feature descriptor for each point. If the point cloud is Nx9, this value should be 6 as in an Nx9 point cloud, 3 of the channels are xyz, and 6 are feature descriptors num_proposal: int (default: 128) Number of proposals/detections generated from the network. Each proposal is a 3D OBB with a semantic class. vote_factor: (default: 1) Number of votes generated from each seed point. """ def __init__ (self, num_class, num_heading_bin, num_size_cluster, mean_size_arr, input_feature_dim=0 , num_proposal=128 , vote_factor=1 , sampling='vote_fps' ): super ().__init__() ... ... self.backbone_net = Pointnet2Backbone(input_feature_dim=self.input_feature_dim) self.vgen = VotingModule(self.vote_factor, 256 ) self.pnet = ProposalModule(num_class, num_heading_bin, num_size_cluster, mean_size_arr, num_proposal, sampling) def forward (self, inputs ): """ Forward pass of the network Args: inputs: dict {point_clouds} point_clouds: Variable(torch.cuda.FloatTensor) (B, N, 3 + input_channels) tensor Point cloud to run predicts on Each point in the point-cloud MUST be formated as (x, y, z, features...) Returns: end_points: dict """ end_points = {} batch_size = inputs['point_clouds' ].shape[0 ] end_points = self.backbone_net(inputs['point_clouds' ], end_points) xyz = end_points['fp2_xyz' ] features = end_points['fp2_features' ] end_points['seed_inds' ] = end_points['fp2_inds' ] end_points['seed_xyz' ] = xyz end_points['seed_features' ] = features xyz, features = self.vgen(xyz, features) features_norm = torch.norm(features, p=2 , dim=1 ) features = features.div(features_norm.unsqueeze(1 )) end_points['vote_xyz' ] = xyz end_points['vote_features' ] = features end_points = self.pnet(xyz, features, end_points) return end_points
voting_module.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class VotingModule (nn.Module ): def __init__ (self, vote_factor, seed_feature_dim ): """ Votes generation from seed point features. Args: vote_facotr: int number of votes generated from each seed point seed_feature_dim: int number of channels of seed point features vote_feature_dim: int number of channels of vote features """ super ().__init__() self.vote_factor = vote_factor self.in_dim = seed_feature_dim self.out_dim = self.in_dim self.conv1 = torch.nn.Conv1d(self.in_dim, self.in_dim, 1 ) self.conv2 = torch.nn.Conv1d(self.in_dim, self.in_dim, 1 ) self.conv3 = torch.nn.Conv1d(self.in_dim, (3 +self.out_dim) * self.vote_factor, 1 ) self.bn1 = torch.nn.BatchNorm1d(self.in_dim) self.bn2 = torch.nn.BatchNorm1d(self.in_dim) def forward (self, seed_xyz, seed_features ): """ Forward pass. Arguments: seed_xyz: (batch_size, num_seed, 3) seed_features: (batch_size, feature_dim, num_seed) Returns: vote_xyz: (batch_size, num_seed*vote_factor, 3) vote_features: (batch_size, vote_feature_dim, num_seed*vote_factor) """ batch_size = seed_xyz.shape[0 ] num_seed = seed_xyz.shape[1 ] num_vote = num_seed * self.vote_factor net = F.relu(self.bn1(self.conv1(seed_features))) net = F.relu(self.bn2(self.conv2(net))) net = self.conv3(net) net = net.transpose(2 ,1 ).view(batch_size, num_seed, self.vote_factor, 3 +self.out_dim) offset = net[:,:,:,0 :3 ] vote_xyz = seed_xyz.unsqueeze(2 ) + offset vote_xyz = vote_xyz.contiguous().view(batch_size, num_vote, 3 ) residual_features = net[:,:,:,3 :] vote_features = seed_features.transpose(2 ,1 ).unsqueeze(2 ) + residual_features vote_features = vote_features.contiguous().view(batch_size, num_vote, self.out_dim) vote_features = vote_features.transpose(2 ,1 ).contiguous() return vote_xyz, vote_features
proposal_module.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 class ProposalModule (nn.Module ): def __init__ (self, num_class, num_heading_bin, num_size_cluster, mean_size_arr, num_proposal, sampling, seed_feat_dim=256 ): super ().__init__() ... ... self.vote_aggregation = PointnetSAModuleVotes( npoint=self.num_proposal, radius=0.3 , nsample=16 , mlp=[self.seed_feat_dim, 128 , 128 , 128 ], use_xyz=True , normalize_xyz=True ) self.conv1 = torch.nn.Conv1d(128 ,128 ,1 ) self.conv2 = torch.nn.Conv1d(128 ,128 ,1 ) self.conv3 = torch.nn.Conv1d(128 ,2 + 3 + num_heading_bin * 2 + num_size_cluster * 4 + self.num_class,1 ) self.bn1 = torch.nn.BatchNorm1d(128 ) self.bn2 = torch.nn.BatchNorm1d(128 ) def forward (self, xyz, features, end_points ): """ Args: xyz: (batch_size, num_vote, 3) features: (batch_size, out_dim, num_vote) Returns: scores: (batch_size, num_proposal, 2 + 3 + NH * 2 + NS * 4) """ if self.sampling == 'vote_fps' : xyz, features, fps_inds = self.vote_aggregation(xyz, features) sample_inds = fps_inds elif self.sampling == 'seed_fps' : sample_inds = pointnet2_utils.furthest_point_sample(end_points['seed_xyz' ], self.num_proposal) xyz, features, _ = self.vote_aggregation(xyz, features, sample_inds) elif self.sampling == 'random' : num_seed = end_points['seed_xyz' ].shape[1 ] batch_size = end_points['seed_xyz' ].shape[0 ] sample_inds = torch.randint(0 , num_seed, (batch_size, self.num_proposal), dtype=torch.int ).cuda() xyz, features, _ = self.vote_aggregation(xyz, features, sample_inds) end_points['aggregated_vote_xyz' ] = xyz end_points['aggregated_vote_inds' ] = sample_inds net = F.relu(self.bn1(self.conv1(features))) net = F.relu(self.bn2(self.conv2(net))) net = self.conv3(net) end_points = decode_scores(net, end_points, self.num_class, self.num_heading_bin, self.num_size_cluster, self.mean_size_arr) return end_points def decode_scores (net, end_points, num_class, num_heading_bin, num_size_cluster, mean_size_arr ): net_transposed = net.transpose(2 ,1 ) batch_size = net_transposed.shape[0 ] num_proposal = net_transposed.shape[1 ] objectness_scores = net_transposed[:,:,0 :2 ] end_points['objectness_scores' ] = objectness_scores base_xyz = end_points['aggregated_vote_xyz' ] center = base_xyz + net_transposed[:, :, 2 :5 ] end_points['center' ] = center heading_scores = net_transposed[:, :, 5 :5 + num_heading_bin] end_points['heading_scores' ] = heading_scores heading_residuals_normalized = net_transposed[:, :, 5 + num_heading_bin:5 + num_heading_bin * 2 ] end_points['heading_residuals_normalized' ] = heading_residuals_normalized end_points['heading_residuals' ] = heading_residuals_normalized * (np.pi / num_heading_bin) size_scores = net_transposed[:, :, 5 + num_heading_bin * 2 :5 + num_heading_bin * 2 + num_size_cluster] end_points['size_scores' ] = size_scores size_residuals_normalized = net_transposed[:, :, 5 + num_heading_bin * 2 + num_size_cluster:5 + num_heading_bin * 2 + num_size_cluster * 4 ].view([batch_size, num_proposal, num_size_cluster, 3 ]) end_points['size_residuals_normalized' ] = size_residuals_normalized end_points['size_residuals' ] = size_residuals_normalized * torch.from_numpy(mean_size_arr.astype(np.float32)).cuda().unsqueeze(0 ).unsqueeze(0 ) sem_cls_scores = net_transposed[:,:,5 + num_heading_bin * 2 + num_size_cluster * 4 :] end_points['sem_cls_scores' ] = sem_cls_scores return end_points
在默认情况下,我们decode_scores对256个检测框每个输出12个heading分类和12个heading的res,10个size分类和10个size的res,3个中心点的坐标,2个代表有无目标,以及10类分类的置信度。
loss_helper.py VoteNet的总的Loss由vote_loss, objectness_loss, box loss, sem cls loss组成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def get_loss (end_points, config ): vote_loss = compute_vote_loss(end_points) end_points['vote_loss' ] = vote_loss objectness_loss, objectness_label, objectness_mask, object_assignment = compute_objectness_loss(end_points) end_points['objectness_loss' ] = objectness_loss end_points['objectness_label' ] = objectness_label end_points['objectness_mask' ] = objectness_mask end_points['object_assignment' ] = object_assignment total_num_proposal = objectness_label.shape[0 ]*objectness_label.shape[1 ] end_points['pos_ratio' ] = torch.sum (objectness_label.float ().cuda())/float (total_num_proposal) end_points['neg_ratio' ] = torch.sum (objectness_mask.float ())/float (total_num_proposal) - end_points['pos_ratio' ] center_loss, heading_cls_loss, heading_reg_loss, size_cls_loss, size_reg_loss, sem_cls_loss = \ compute_box_and_sem_cls_loss(end_points, config) end_points['center_loss' ] = center_loss end_points['heading_cls_loss' ] = heading_cls_loss end_points['heading_reg_loss' ] = heading_reg_loss end_points['size_cls_loss' ] = size_cls_loss end_points['size_reg_loss' ] = size_reg_loss end_points['sem_cls_loss' ] = sem_cls_loss box_loss = center_loss + 0.1 *heading_cls_loss + heading_reg_loss + 0.1 *size_cls_loss + size_reg_loss end_points['box_loss' ] = box_loss loss = vote_loss + 0.5 *objectness_loss + box_loss + 0.1 *sem_cls_loss loss *= 10 end_points['loss' ] = loss obj_pred_val = torch.argmax(end_points['objectness_scores' ], 2 ) obj_acc = torch.sum ((obj_pred_val==objectness_label.long()).float ()*objectness_mask)/(torch.sum (objectness_mask)+1e-6 ) end_points['obj_acc' ] = obj_acc return loss, end_points
vote loss 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def compute_vote_loss (end_points ): """ Compute vote loss: Match predicted votes to GT votes. Overall idea: 如果我们的seed point属于一个物体(votes_label_mask == 1),那么我们需要它向着物体中心投票 每个seed point可能投票出多个translation v1,v2,v3 一个seed point也可能在多个物体o1,o2,o3的bounding box中,对应的GT vote为 c1, c2, c3 对于这个seed point的loss为: min(d(v_i,c_j)) for i=1,2,3 and j=1,2,3 """ batch_size = end_points['seed_xyz' ].shape[0 ] num_seed = end_points['seed_xyz' ].shape[1 ] vote_xyz = end_points['vote_xyz' ] seed_inds = end_points['seed_inds' ].long() seed_gt_votes_mask = torch.gather(end_points['vote_label_mask' ], 1 , seed_inds) seed_inds_expand = seed_inds.view(batch_size,num_seed,1 ).repeat(1 , 1 , 3 * GT_VOTE_FACTOR) seed_gt_votes = torch.gather(end_points['vote_label' ], 1 , seed_inds_expand) seed_gt_votes += end_points['seed_xyz' ].repeat(1 , 1 , 3 ) vote_xyz_reshape = vote_xyz.view(batch_size*num_seed, -1 , 3 ) seed_gt_votes_reshape = seed_gt_votes.view(batch_size*num_seed, GT_VOTE_FACTOR, 3 ) dist1, _, dist2, _ = nn_distance(vote_xyz_reshape, seed_gt_votes_reshape, l1=True ) votes_dist, _ = torch.min (dist2, dim=1 ) votes_dist = votes_dist.view(batch_size, num_seed) vote_loss = torch.sum (votes_dist * seed_gt_votes_mask.float ()) / (torch.sum (seed_gt_votes_mask.float ()) + 1e-6 ) return vote_loss
objectness loss 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def compute_objectness_loss (end_points ): """ Compute objectness loss for the proposals. Args: end_points: dict (read-only) Returns: objectness_loss: scalar Tensor objectness_label: (batch_size, num_seed) Tensor with value 0 or 1 objectness_mask: (batch_size, num_seed) Tensor with value 0 or 1 object_assignment: (batch_size, num_seed) Tensor with long int within [0,num_gt_object-1] """ aggregated_vote_xyz = end_points['aggregated_vote_xyz' ] gt_center = end_points['center_label' ][:,:,0 :3 ] B = gt_center.shape[0 ] K = aggregated_vote_xyz.shape[1 ] K2 = gt_center.shape[1 ] dist1, ind1, dist2, _ = nn_distance(aggregated_vote_xyz, gt_center) euclidean_dist1 = torch.sqrt(dist1+1e-6 ) objectness_label = torch.zeros((B,K), dtype=torch.long).cuda() objectness_mask = torch.zeros((B,K)).cuda() objectness_label[euclidean_dist1<NEAR_THRESHOLD] = 1 objectness_mask[euclidean_dist1<NEAR_THRESHOLD] = 1 objectness_mask[euclidean_dist1>FAR_THRESHOLD] = 1 objectness_scores = end_points['objectness_scores' ] criterion = nn.CrossEntropyLoss(torch.Tensor(OBJECTNESS_CLS_WEIGHTS).cuda(), reduction='none' ) objectness_loss = criterion(objectness_scores.transpose(2 ,1 ), objectness_label) objectness_loss = torch.sum (objectness_loss * objectness_mask)/(torch.sum (objectness_mask)+1e-6 ) object_assignment = ind1 return objectness_loss, objectness_label, objectness_mask, object_assignment
box and sem cls loss 论文中的描述如下:
1 The max-pooled features are further processed by MLP2 with output sizes of 128, 128, 5+2NH+4NS+NC where the output consists of 2 objectness scores, 3 center regression values, 2NH numbers for heading regression (NH heading bins) and 4NS numbers for box size regression (NS box anchors) and NC numbers for semantic classification
其实,根据VoteNet引用的Frustum PointNet所提到的,两篇文章都只考虑了Up-axis轴上的角度作为heading angle,对于3D Bounding Box做了2个自由度的简化。那么其实就很容易懂了,把180度分成12份,先预测在哪个bin中,再回归bin内的偏移量是多少。而size bin以及size residual是类似的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 def compute_box_and_sem_cls_loss (end_points, config ): """ Compute 3D bounding box and semantic classification loss. Args: end_points: dict (read-only) Returns: center_loss heading_cls_loss heading_reg_loss size_cls_loss size_reg_loss sem_cls_loss """ num_heading_bin = config.num_heading_bin num_size_cluster = config.num_size_cluster num_class = config.num_class mean_size_arr = config.mean_size_arr object_assignment = end_points['object_assignment' ] batch_size = object_assignment.shape[0 ] pred_center = end_points['center' ] gt_center = end_points['center_label' ][:, :, 0 :3 ] dist1, ind1, dist2, _ = nn_distance(pred_center, gt_center) box_label_mask = end_points['box_label_mask' ] objectness_label = end_points['objectness_label' ].float () centroid_reg_loss1 = torch.sum (dist1 * objectness_label) / (torch.sum (objectness_label) + 1e-6 ) centroid_reg_loss2 = torch.sum (dist2 * box_label_mask) / (torch.sum (box_label_mask) + 1e-6 ) center_loss = centroid_reg_loss1 + centroid_reg_loss2 heading_class_label = torch.gather(end_points['heading_class_label' ], 1 , object_assignment) criterion_heading_class = nn.CrossEntropyLoss(reduction='none' ) heading_class_loss = criterion_heading_class(end_points['heading_scores' ].transpose(2 ,1 ), heading_class_label) heading_class_loss = torch.sum (heading_class_loss * objectness_label) / (torch.sum (objectness_label) + 1e-6 ) heading_residual_label = torch.gather(end_points['heading_residual_label' ], 1 , object_assignment) heading_residual_normalized_label = heading_residual_label / (np.pi/num_heading_bin) heading_label_one_hot = torch.cuda.FloatTensor(batch_size, heading_class_label.shape[1 ], num_heading_bin).zero_() heading_label_one_hot.scatter_(2 , heading_class_label.unsqueeze(-1 ), 1 ) heading_residual_normalized_loss = huber_loss(torch.sum (end_points['heading_residuals_normalized' ] * heading_label_one_hot, -1 ) - heading_residual_normalized_label, delta=1.0 ) heading_residual_normalized_loss = torch.sum (heading_residual_normalized_loss * objectness_label) / (torch.sum (objectness_label)+1e-6 ) size_class_label = torch.gather(end_points['size_class_label' ], 1 , object_assignment) criterion_size_class = nn.CrossEntropyLoss(reduction='none' ) size_class_loss = criterion_size_class(end_points['size_scores' ].transpose(2 ,1 ), size_class_label) size_class_loss = torch.sum (size_class_loss * objectness_label) / (torch.sum (objectness_label) + 1e-6 ) size_residual_label = torch.gather(end_points['size_residual_label' ], 1 , object_assignment.unsqueeze(-1 ).repeat(1 ,1 ,3 )) size_label_one_hot = torch.cuda.FloatTensor(batch_size, size_class_label.shape[1 ], num_size_cluster).zero_() size_label_one_hot.scatter_(2 , size_class_label.unsqueeze(-1 ), 1 ) size_label_one_hot_tiled = size_label_one_hot.unsqueeze(-1 ).repeat(1 ,1 ,1 ,3 ) predicted_size_residual_normalized = torch.sum (end_points['size_residuals_normalized' ]*size_label_one_hot_tiled, 2 ) mean_size_arr_expanded = torch.from_numpy(mean_size_arr.astype(np.float32)).cuda().unsqueeze(0 ).unsqueeze(0 ) mean_size_label = torch.sum (size_label_one_hot_tiled * mean_size_arr_expanded, 2 ) size_residual_label_normalized = size_residual_label / mean_size_label size_residual_normalized_loss = torch.mean(huber_loss(predicted_size_residual_normalized - size_residual_label_normalized, delta=1.0 ), -1 ) size_residual_normalized_loss = torch.sum (size_residual_normalized_loss * objectness_label) / (torch.sum (objectness_label) + 1e-6 ) sem_cls_label = torch.gather(end_points['sem_cls_label' ], 1 , object_assignment) criterion_sem_cls = nn.CrossEntropyLoss(reduction='none' ) sem_cls_loss = criterion_sem_cls(end_points['sem_cls_scores' ].transpose(2 ,1 ), sem_cls_label) sem_cls_loss = torch.sum (sem_cls_loss * objectness_label) / (torch.sum (objectness_label) + 1e-6 ) return center_loss, heading_class_loss, heading_residual_normalized_loss, size_class_loss, size_residual_normalized_loss, sem_cls_loss