(ICRA2021)ScrewNet
ScrewNet论文阅读和源码分析。
核心表述
其实ScrewNet的目的很简单,希望从深度图中直接估计出物体的关节模型及其位形信息,而之前的工作都需要引入额外的关节体的纹理信息、或者指定关节体的类型(rigid、revolute、prismatic,helical)。
ScrewNet的核心结构如下:
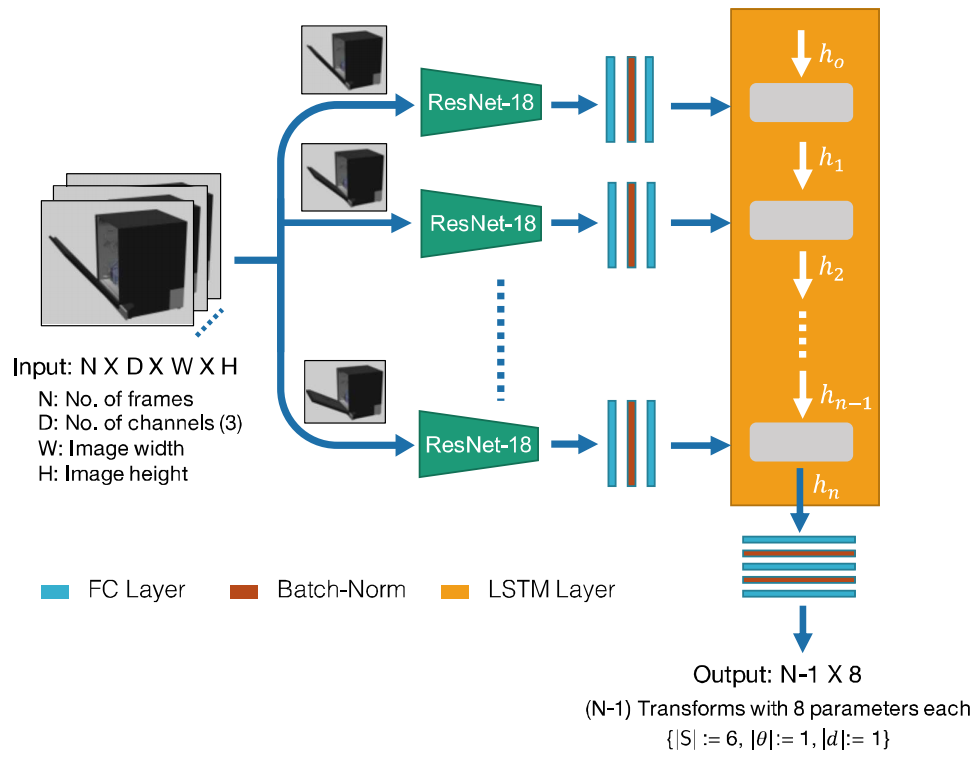
对于N帧深度图,每一帧都先使用ResNet-18作为backbone来提取2D图像特征,然后提取出来的N个特征向量传入到LSTM层中计算,然后输出N-1 X 8个相对的Screw Parameter。此处提供一个复习LSTM的博客。
Screw Theory
这篇文章能中ICRA的点就在于此。“空间中任何一个物体的位移都可以通过绕着一条直线的旋转以及绕着这条线的平行移动解决。”这条线叫做screw axis of displacement $S$。在普吕克坐标系下,直线可以表示成$(\textbf{l}, \textbf{m})$的形式,并且满足$||\textbf{l}||=1$和$\textbf{l}\cdot\textbf{m}=0$这两个约束条件。其实也很容易理解,在欧式坐标下,我们取直线的一段线段,有端点x和y。我们令
$$
\textbf{l}=\text{normalize} (y-x) \
\textbf{m}=x\times y
$$
这就是普吕克坐标下表示直线的方法。
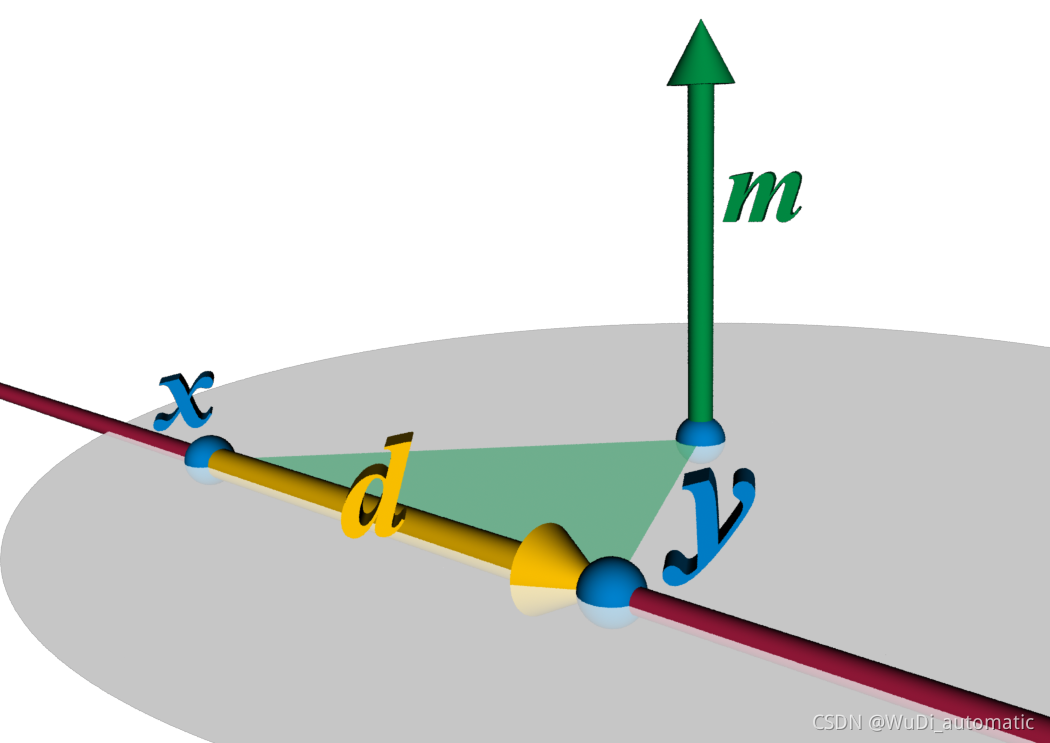
上图中的$(d,m)$就是我们的$(\textbf{l}, \textbf{m})$。
所以ScrewNet就使用了$(\textbf{l}, \textbf{m}, \theta, d)$来表示在SE(3)中的刚体运动。其中$d$是沿着轴的线性平移,而$\theta$是绕着轴的旋转,并且满足$d=h\theta$。
Loss Function
Screw位移包括了两部分:screw轴$S$,以及对应的位形$q_i$。所以ScrewNet希望同时优化如下的多个目标损失:
$$
L=\lambda_1L_{S_{ori}}+\lambda_2L_{S_{dist}}+\lambda_3L_{S_{cons}}+\lambda_4{L_q}
$$
其中$L_{S_{ori}}$惩罚的是screw轴的偏差,所以通过GT轴和screw轴的角度偏差来计算,而$L_{S_{dist}}$是惩罚的是预测的screw轴和GT轴的空间距离,通过普吕克坐标系下的直线距离来表示。即:
$$
d((\textbf{l}_1,\textbf{m}_1),(\textbf{l}_2,\textbf{m}_2))=
\begin{cases}
0, & \text{if $\textbf{l}_1$ and $\textbf{l}_2$ intersect} \\
||\textbf{l}_1\times(\textbf{m}_1-\textbf{m}_2)||, & \text{else if $\textbf{l}_1$ and $\textbf{l}_2$ are parallel, i.e.$||\textbf{l}_1\times \textbf{l}_2||=0$} \\
\frac{|\textbf{l}_1\cdot \textbf{m}_2+\textbf{l}_2 \cdot \textbf{m}_1|}{||\textbf{l}_1\times \textbf{l}_2||}, & else,\textbf{l}_1\ and\ \textbf{l}_2\ are\ skew\ lines
\end{cases}\\
L_{S_{dist}}=d((\textbf{l}_{GT},\textbf{m}_{GT}),(\textbf{l}_{pred},\textbf{m}_{pred}))
$$
而$L_{S_{cons}}$强迫其满足预测出来的直线满足普吕克约束$(\textbf{l}\cdot\textbf{m}=0)$和$||\textbf{l}||=1$;$L_q$是位形损失。
其中$L_q$可以由两部分组成:旋转误差$L_{\theta}$和平移误差$L_d$,如下计算:
$$
L_q=\alpha_1L_{\theta}+\alpha_2L_d \\
L_{\theta}=I_{3\times3}-R(\theta_{GT},\textbf{l}_{GT})R(\theta_{pred},\textbf{l}_{pred})^T \\
L_d=||d_{GT}\cdot\textbf{l}_{GT}-d_{pred}\cdot\textbf{l}_{pred}||
$$
其中的$R(\theta,\textbf{l})$就是沿着轴$\textbf{l}$旋转$\theta$角度的旋转矩阵$R$。之所以不直接对$q_{GT}$和$q_{pred}$施加$L_2$损失是因为这个损失函数的构成确保了其物理的含义,因为这个损失函数是基于旋转矩阵正交的性质而设计的,所以它可以确保学出来的$\theta_{pred}$和$\textbf{l}_{pred}$是满足$R(\theta_{pred},\textbf{l}_{pred})\in SO(3)$。类似的,损失函数$L_d$也计算了沿着两根不同的轴$\textbf{l}_{GT}$和$\textbf{l}_{pred}$的平移误差,如果我们只是计算$d_{GT}$和$d_{pred}$的范数的话,就等于我们默认了它们是沿着同一个轴平移的,这就不合理。
综上所述,我们Loss函数的选取遵循了我们所提出的Screw理论。
打标签方法
ScrewNet的训练集包括了一系列的深度图像,并且需要有对应的screw displacement。使用Mujoco来渲染仿真中的关节体并且记录深度图像。使用了数据集中的柜子、抽屉、微波炉、烤箱等。
为了创建screw displacement标签,我们考虑$o_i$作为基物体,然后我们计算后面的$o_j$相对于基物体的相对screw displacement。具体来说,就是给定一个N帧图片的视频流$I_{1:N}$,我们首先选定视频的第一帧是物体的基础位姿,然后计算出n-1帧的相对的screw displacement。
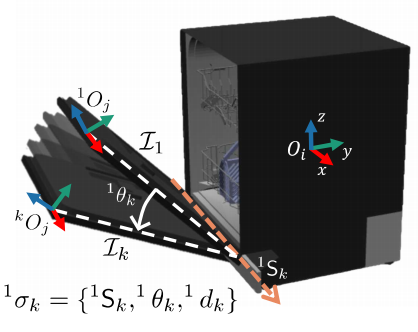
也就是我们有相对于坐标系$F_{O_j^1}$的n-1个位移了,我们可以通过在普吕克坐标下做变换把这n-1个相对位移全部转换到相对于基坐标轴$O_i$下。具体的普吕克坐标系下的变换形式可以参考原文。
代码实现
1.models.py
在代码中,ScrewNet提供了三个模型:ScrewNet、ScrewNet_2imgs、ScrewNet_NoLSTM,在实际训练和测试中,和数据集的对应关系如下:
1 | if args.model_type == '2imgs': |
其中ScrewNet_2imgs似乎是一个降级版本,我们先从这个模型的源码开始读起:
1 | class ScrewNet_2imgs(nn.Module): |
其中的models.resnet18()其实是torchvision.models.resnet.py中帮我们实现好的resnet,我们可以单纯地认为输入B * 3 * W * H,输出一个B * 1000的ResNet特征。
接下来是No_LSTM版本的ScrewNet:
1 | class ScrewNet(nn.Module): |
这里涉及到LSTM的输入和输出,可以参考官网上的参数介绍。注意到最后的全连接层的维度变化,最后之所以预测B * 8N,是因为每个样本都有N帧,我们需要预测出每一帧的关节体参数,至于为什么不是$B \times N \times8$,这倒不是很重要,反正在back propagation的时候我们只需要准确地实现loss function,都能回归出来。
代码中还提供了一个no_lstm版本,
1 | class ScrewNet_NoLSTM(nn.Module): |
loss.py
1 | def articulation_lstm_loss_spatial_distance(pred, target, wt_on_ortho=1.): |
2.dataset.py
我们先从简单的两张图片的数据集RigidTransformDataset入手,注意到数据集只需要override __len__和 __getitem__。
1 | """ |
多张图片的其实就大差不差了,不过里面有一个细节我们需要深究一下。
1 | class ArticulationDataset(Dataset): |
只有理解了transform_to_screw这个函数在做什么,我们才真正摸索到了Screw Theory的实质。主要可以参考这篇文献。总体逻辑就是四元数可以表示三维旋转,而对偶四元数可以同时表示三维旋转和平移,所以使用对偶四元数来表示Screw Parameter就是很合理的事情,满足以下推导:
空间任意刚体运动,可分解为刚体上某一点的平移,以及绕经过此点的旋转轴的转动,我们令这个点为连体基坐标原点,我们记作$R$和$t$,旋转矩阵$R$对应的四元数为$p$,由$R$和$t$可以计算出对偶四元数$q$。根据Chasles theorem(Screw theory,沙勒定理)我们又知道:空间任意刚体运动,均可看作有限螺旋运动,即均可表示为绕一轴的旋转和沿该轴的平移,参数可以记为$(\textbf{l},\textbf{m}, \theta, d)$。
首先,四元数$p$转化为轴角表达$p=(cos(\frac{\theta}{2}),\textbf{l}sin(\frac{\theta}{2}))$就可以直接得到$\textbf{l}$和$\theta$,参数物理意义完全相同。其余参数满足下式:
$$
d=\textbf{t}\cdot\textbf{l}=(2qp^*)\cdot\textbf{l} \\
m=\frac{1}{2}(\textbf{t}\times\textbf{l}+(\textbf{t}-d\textbf{l})\cot\frac{\theta}{2})
$$
3.train_model.py
里面涉及到三种不同的模型的定义,封装地也很好,总体逻辑还是非常简单易懂的。
1 | trainset = ... |
4.model_trainer.py
其实这就没啥好说的了,无非就是训练(算loss,反向传播,画图,训练日志,保存模型)和测试(计算均值和方差)。
1 |
|
5.Other Modules
其他辅助模组就暂时不继续占据篇幅了。注意到还存在一个noisy_models.py,引用了这个仓库,可能是对应的paper的数据增强手段,此处不表。
(ICRA2021)ScrewNet