complier-lab5
This lab comes from SE3355 *Compilers* lab5, which requires me to implement a complete runnable tiger compiler.
致谢:Lab5的完成离不开Girafboy学长仓库所提供的参考和思路,为了避免有抄袭之嫌,我将重新以我的思路阐述清楚我的代码。
首先明确,我们这个Lab5的目标是把做完escape analysis的AST转化为tree language(middle IR),再转化为assem(lower IR)。正如院长所说,前4个Lab其实是把代码文本转化成了AST,只生成了一个IR,但是我们需要在Lab5一下子完成两个IR的转换和生成,并且我们生成tree language后,其实非常不好Debug,因为有各种各样的嵌套语句,也没有解释器来解析tree language,我们必须等到生成了assem后才能够被汇编解释器所解释执行。
Part1 AST翻译成Tree Language
前半部分是根据AST翻译成tree language。这部分相对比较简单,但是一件很麻烦的事情就是translation和Lab4的semantic analysis是非常紧密地intertwine在一起的,如果我们希望在Translate中调用SemAnalyze,会导致大量的代码重构,基本上是一整个Lab4的工作量加上额外的Debug时间,并且还涉及到一个非常trivial,还是很麻烦的点:
1 | type::Ty *SemAnalyze(env::VEnvPtr venv, env::TEnvPtr tenv, int labelcount, |
我们可以看到,在模板所提供的的接口定义中,Translate函数是没有labelcount参数的,所以它并不能判断某个break语句是否在某些循环语句的里面,我们必须使用SemAnalyze来判定这个错误,所以哪怕我们把语义分析的语句全部迁移到Translate中,还是会有这个问题。为了避免过于丑陋的实现,我在这里纠结了一段时间,不过后来我仔细地查看了Lab5的测试代码(而不是Lab5-part1,Lab5-part1测试脚本没有Semantic analysis阶段,误导了我很久),如下所示:
1 | ... |
所以虽然上课说应该在translation的时候做同时做类型检查的,在Lab中评测中还是没有要求的这么严格。为了避免在Translate阶段又做一遍类型检查,我对AST上的所有节点添加了一个成员type::Ty *type,这样我们做完SemAnalyze后就可以缓存住每个节点的真正类型,然后在Translate阶段使用。这样我们基本上就完成了做Translate的准备动作。
Translate接口的定义如下:
1 | tr::ExpAndTy *Translate(env::VEnvPtr venv, env::TEnvPtr tenv, |
解决掉Translate的关键就是理解level和label参数的含义,理解了自然后面就都好做了。
我们先来看label,涉及到label修改和使用的只有两处:
1 | tr::ExpAndTy *WhileExp::Translate(env::VEnvPtr venv, env::TEnvPtr tenv, |
注意到for循环最终是规约到while的,所以for循环没有使用到label。这样我们就很清楚了,label就是为了让break语句跳出循环使用的。换句话说,就是循环中done:的位置。这样看来,如果我们希望在translation中一遍同时做类型检查,没有labelcount也无伤大雅,我们只需要判断label是不是等于外面传入的默认值即可。
接下来是level函数,它主要的意义就是负责static link。换句话说,如果我们在$level=k_1$的函数体中引用到了$level=k_2<k_1$的变量,那么我们需要通过$k_1-k_2$次static link跳转,找到这个变量所在的frame,并且通过其InReg还是InFrame来获取到具体的值。
所以,level的修改只会出现在FunctionDec的时候:
1 | tr::Exp *FunctionDec::Translate(env::VEnvPtr venv, env::TEnvPtr tenv, |
StaticLink的处理
static link的核心逻辑如下所示:
1 | tree::Exp *StaticLink(tr::Level *target, tr::Level *level) { |
当我们在某个函数中尝试使用一个变量的时候,我们需要在venv中找到此变量的定义层数,并且调用StaticLink函数找到对应的层数。
1 | tr::Exp *TranslateSimpleVar(tr::Access *access, tr::Level *level) { |
注意在CallExp中,如果我们是外部调用的话,不需要添加static link参数,因为外部调用要求不传入static link。
外部调用的处理
1 | tree::Exp *externalCall(std::string s, tree::ExpList *args) { |
关系运算的翻译
1 | case EQ_OP: |
其实就是一个CxExp的构造,我们需要把true_label和false_label的地址传入,以便之后回填。
Part2 Tree Language翻译成Assem
基本数据结构
1 | class Frame { |
Frame主要是存放函数的名字、寄存器的escape信息、以及栈上的分配offset。
1 | class X64RegManager : public RegManager { |
其他情况
其他情况不再赘述,详见之后公开的Github仓库。
ProcEntryExit1
主要是用来做view shift的,也就是把传入的寄存器参数存放到函数内来看它的位置。强调我的实现只是完成了功能,并没有性能上的考虑。所以,考虑到多个参数的情况,我先把所有传入的寄存器上的值和6个参数以外的栈上的值全部移到临时寄存器中,再重新根据我们的需要安排到栈上,此处的多余move应当是不必要的。
1 | tree::Stm *procEntryExit1(frame::Frame *frame, tree::Stm *stm) { |
ProcEntryExit2
ProcEntryExit2是要在翻译完的body instruction后添加一条空指令,告诉我们函数结束的时候哪些寄存器是要被用到的。
1 | assem::InstrList *procEntryExit2(assem::InstrList *body) { |
ProcEntryExit3
ProcEntryExit3生成过程入口处理和出口处理的汇编语言代码,主要是对栈指针的更改,以及设置framesize变量。
1 | assem::Proc *procEntryExit3(frame::Frame *frame, assem::InstrList * body) { |
处理传入大于6个参数的函数调用的情况
首先,我们在tigermain中存在一个返回值-1,所以当我们主程序结束后,会根据这个-1跳转到run函数的循环。
1 | # interpreter.py |
如下图所示,我们目前创造了A的栈帧,并且把传入的参数都根据其是否逃逸放到了对应的寄存器和栈上。
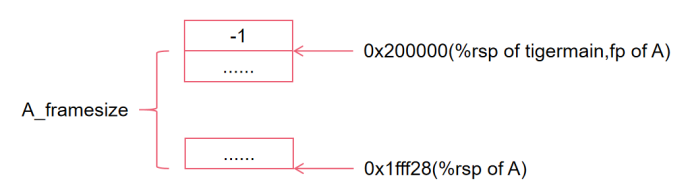
我们假设此时A希望调用函数B,并且需要传入8个参数+1个static link,由于传参寄存器只有6个,所以后两个参数(记作23和45)和static link都需要放在栈上。
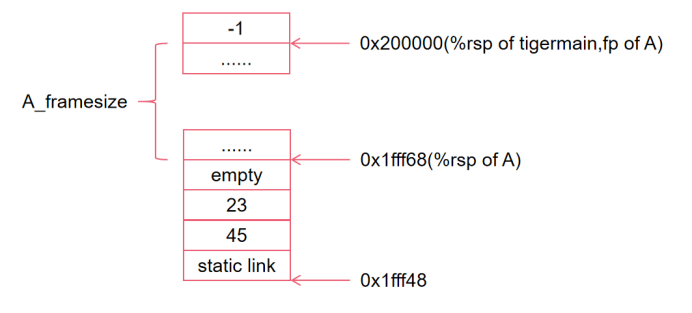
注意此时,在%rsp-8处我们需要填充一个空的八字节,然后再依次放入23,45和static link。上图为call(B)前的栈上状态。
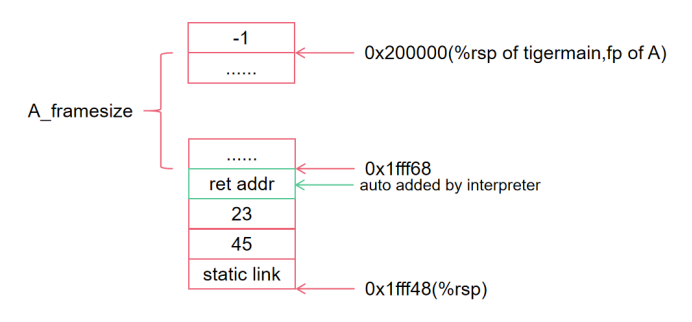
在call(B)后,解释器会帮我们填入A的返回地址pc的位置,所以这八个字节是要空出来的,如上图所示。
1 | # state_table.py |
如下图所示,这是我们调用call(B)瞬间,还没有对传入参数做寄存器和栈分配时,栈上的情况。
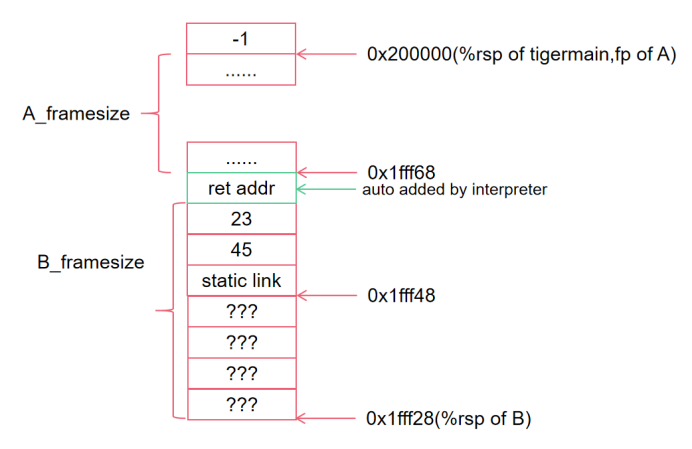
接下来,我们继续对寄存器做escape allocation,最终得到一个完整的B运行时栈。
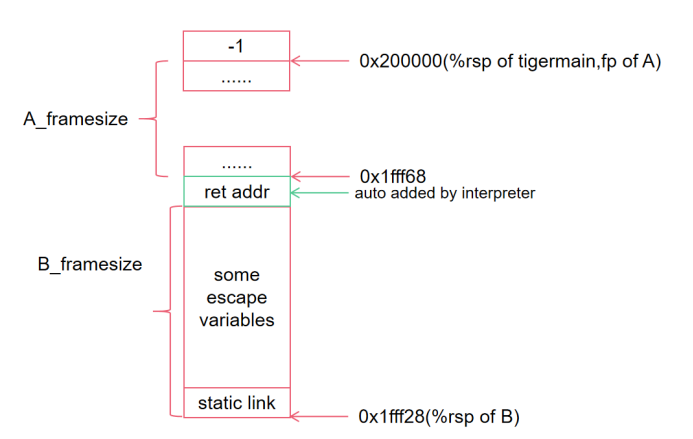
故代码如下:
1 | temp::TempList *ExpList::MunchArgs(assem::InstrList &instr_list, std::string_view fs) { |
complier-lab5