CHOMP_and_related_works
最近深感自己知识储备的不足,面对一个问题可能前人已经解决了,但是却自己根本摸不着头绪。准备好好开始看paper来增加自己的知识库储备。实验室的师兄师姐们都非常厉害,分分钟可以丢给我很多paper去看,希望借此机会可以增加自己研究的insight。
CHOMP
CHOMP是一篇如雷贯耳的文章。刚进领域的时候就经常看见CHOMP,STOMP等planner,非常如雷贯耳,最近项目可能要添加进一些planner的因素,所以要先从这篇09年ICRA的祖师爷开始看起,注意同一批人在13年再次对CHOMP工作做了细致的讲解、提供了和RRT*的对比实验,并且提供了扩展到含额外约束的轨迹规划问题上。
其实CHOMP的思路比较直观,它有一个目标函数$U(\xi)=f_{prior}(\xi)+\lambda f_{obstacle}(\xi)$,最终目标就是优化这个目标函数得到轨迹$\xi$。即有:
$$
\xi^* = \mathop{\arg\min}_{\xi}U(\xi)
$$
其中,轨迹$\xi(t)$可以认为是一个[0,1]$\rightarrow R^m$的函数,我们把时间归一化到0~1之间,也就是说$\xi(0)=q_{init}$以及$\xi(1)=q_{goal}$。所以$U(\xi)$就可以简单地认为是一个关于轨迹$\xi$的损失函数。当它取到最小的时候我们即得到了一个最优的colision-free的轨迹。
动力学损失函数
CHOMP的目标函数主要考虑了动力学带来的cost以及碰撞所带来的cost。我们可以先看动力学所带来的cost。$f_{prior}(\xi)=\displaystyle\frac{1}{2}\int^1_0 \vert|\frac{d}{dt}\xi(t)||^2 dt$,这一项是直接对轨迹的速度的平方做积分,也可以扩展到加速度和加加速度的情况,是用来鼓励轨迹更加顺滑的。
碰撞损失函数
第二个损失函数就是说CHOMP希望规划出一条collision-free的轨迹,所以必须要把场景中的所有障碍物全部考虑进去。我们考虑机械臂外表面上的点集$B\subset R^3$, u是其上一点。在某个构型下,我们显然可以通过构型的前向动力学信息以及机械臂上的相对坐标计算出其在欧式空间中的瞬时绝对坐标,我们记为$x(\xi(t),u)$,有了这个坐标以后,那我们需要得到这一点离障碍物的距离,我们希望尽可能提升这个距离。所以我们引入了SDF距离(有向距离场),这个在图像渲染中用到的比较多,其实就是这个点到一个物体表面的最短距离。有了这个距离度量函数,我们可以构造出大于0的损失函数来尽可能最大化这个距离度量。所以我们有碰撞损失函数:
$$
\displaystyle f_{obstacle}=\int_0^1\int_B c_{obstacle}(x(\xi(t), u))|\frac{d}{dt}x(\xi(t),u)|dudt
$$
在上式中,其实对机械臂的表面积做积分这件事情是比较显然的,但是之前一直很难理解为什么要乘上这个速度函数$x’(\xi(t),u)=v(\xi,u)$。理解起来也不复杂,因为我们的轨迹的时间归一化到了0~1之间。所以如果不乘上这个速度因子的话,就有可能导致两条运动速度不同而位置相同的轨迹算出来的损失函数是相等的,但是我们希望让以较快速度通过的有更大的损失,可能是因为较大的速度更容易碰撞时产生实际的负面影响,所以加上了速度因子后,就把时间归一化带来的多解问题消除掉了,可以理解为是一个保序变换。
优化过程
论文使用迭代的方式来更新轨迹$\xi_k$,使用一阶泰勒展开$U(\xi)\approx U(\xi_k)+g_k^T(\xi-\xi_k)$,其中$g_k=\nabla U(\xi_k)$。
$$
\xi_{k+1}=\xi_k-\frac{1}{\lambda}M^{-1}g_k
$$
推广到含约束的优化过程
有些轨迹创建过程可能需要额外的约束,比如传递水杯的时候我们可能希望水不要洒出来。所以在2013年的文章中,作者对把原先的CHOMP泛化到比较普遍的约束问题上。首先作者假设所有约束都可以按照轨迹在希尔伯特空间上非线性的可微分向量函数来定义:$H:\Xi\rightarrow R^k$,其中的$H(\xi)=0$就是所有满足要求的约束的轨迹。
所以其实就是在我们之前的迭代过程中,我们此时迭代改写为:
$$
\xi_{k+1}=\xi_k-\frac{1}{\lambda}M^{-1}g_k \\
s.t. H[\xi]=0
$$
为了得到一个具体的更新规则,我们在$\xi_i$处对函数H进行一阶泰勒展开,也就是$H(\xi)\approx H(\xi_i)+\frac{\partial}{\partial\xi}H(\xi_i)(\xi-\xi_i)=C(\xi-\xi_i)+b$其中C是约束函数的Jacobian,而$b=H(\xi_i)$,我们可以把带约束的迭代问题转化为拉格朗日约束下的梯度下降问题,具体过程不再描述。最终我们得到的更新规则为:
$$
\xi_{k+1}=\xi_k-\frac{1}{\lambda}A^{-1}g_k+\frac{1}{\lambda}A^{-1}C^T(CA^{-1}C^T)^{-1}CA^{-1}g_{k}-A^{-1}C^T(CA^{-1}C^T)^{-1}b
$$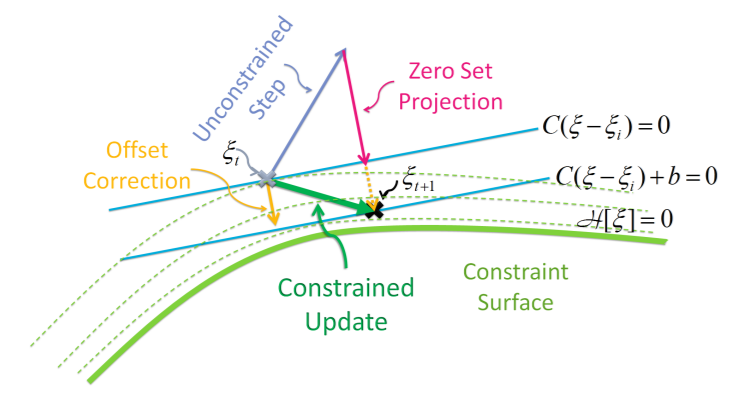
其实就是说在带约束的更新规则下,它先以无约束的方式优化一步,然后把A投影到穿过$\xi_t$的超平面上,并且这个超平面与我们的约束函数在$\xi_i$处的一阶泰勒展开的近似超平面$C(\xi-\xi_i)+b=0$平行。最终,它消除掉了两个超平面之间的平移量,使得下一步迭代$\xi_{i+1}$更加接近于约束函数$H(\xi)=0$上。
所以其实我们如果能够形式化定义出这个$H(\xi)$的具体形式,那么找到满足这个约束的轨迹也只是一个优化的过程。
[RSS2020] 在线抓取合成和优化的轨迹创建
摘要的大致意思就是说轨迹创建和Grasp预测通常是分别处理的,这篇文章希望提出一个整合两个planning问题的方法。这篇文章整合出了一个轨迹优化方法和在线抓点合成/选取的一个结合办法,也就是在线学习并且挑选出最终抓点的6D pose。并且证明了在复杂环境中是可以鲁棒并且高效地创建出motion plan的。
避障自然就是使用了CHOMP算法,不再过多叙述。和这篇文章主打的Grasp相关的概念:给定一个场景中的多个物体,定义了可行的目标物体抓取集合$G\subseteq Q\subseteq R^d$。这样我们的优化问题就变成了:
$$
\xi^* = \mathop{\arg\min}_{\xi}f_{motion}(\xi) \\
s.t.\xi(1)\in G
$$
其中的损失函数$f_{motion}$自然就是CHOMP中的$U(\xi)$,即$f_{motion}(\xi)=f_{obstacle}(\xi)+\lambda f_{prior}(\xi)$。所以这一步其实就是CHOMP含约束优化的一个实例。约束函数定义为$H(\xi_i)=\xi_i-g=0$,我们可以使用CHOMP含约束的更新规则来进行更新。我们可以定义$f_g(\xi_i)$是在第i次迭代时,使用g作为目标抓点的损失函数。稍微有一点点不同的地方在于在不同迭代中选择的抓点g可能是不一样的。
在线学习抓点选择
如果我们直接使用CHOMP求解带约束g的优化函数,那么我们并没有考虑到一些轨迹上的特性,比如这篇ISRR2011所提到的损失函数可能陷入局部最优的情况。
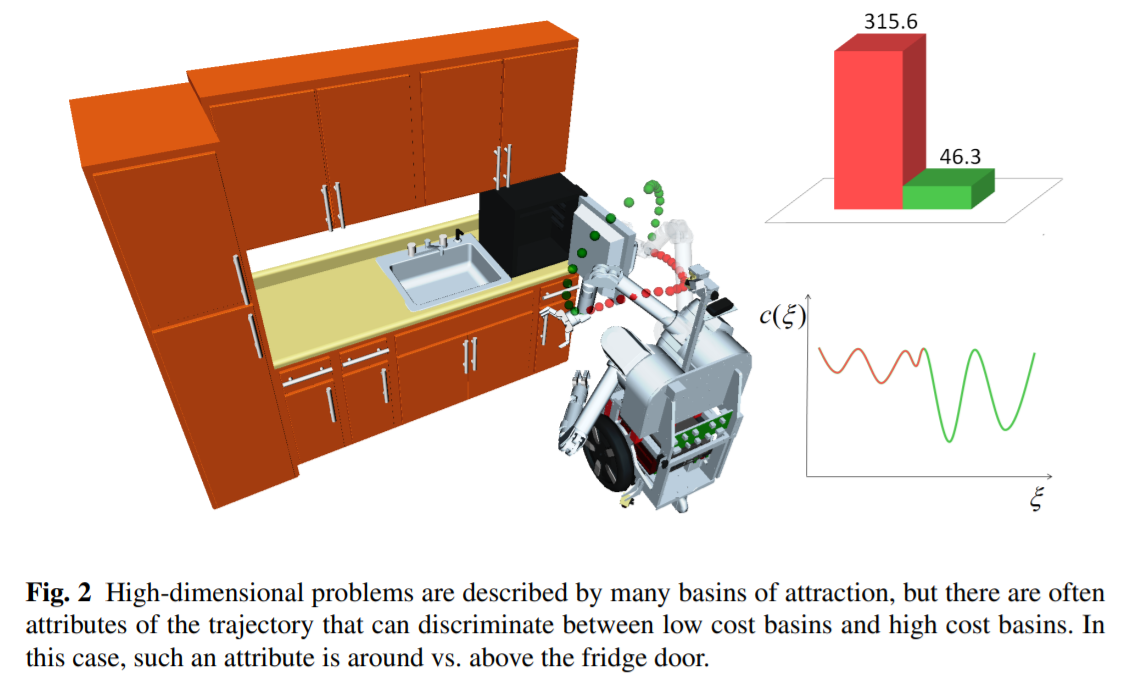
如上图所示,这个例子如果我们梯度下降的起点选择的不好就很容易会陷入局部最优的情况,这是从机器学习角度是很容易理解的事情。不过,我们可以通过额外要求满足轨迹的一些Attributes来限定梯度下降的区域(起点)就是在那个可以达到局部最优的位置。
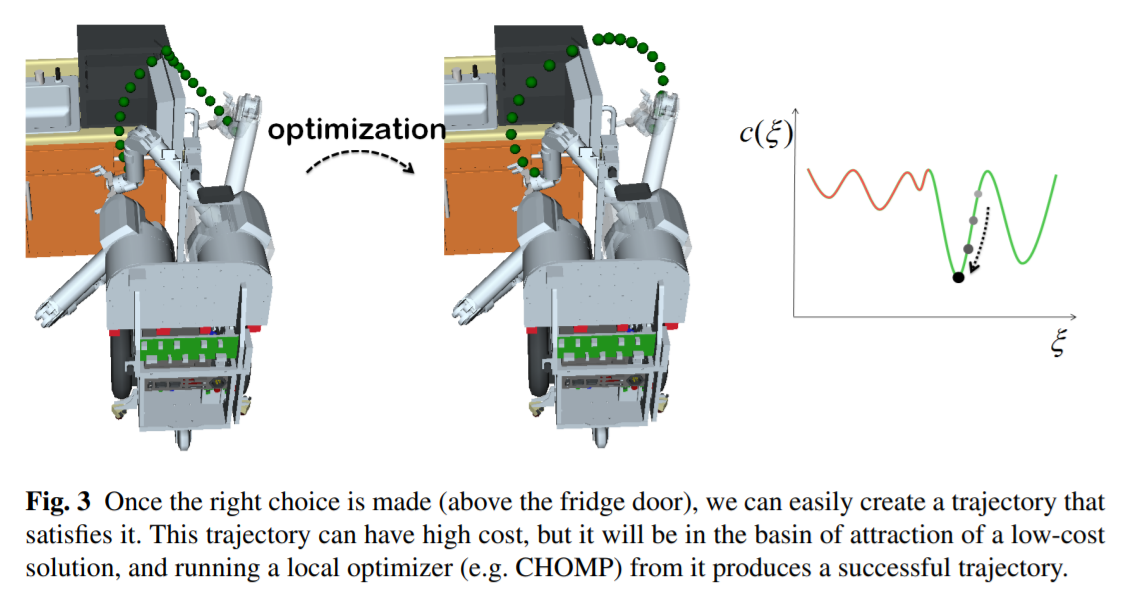
如上图所示,如果我们规定,所有轨迹都要满足“都从冰箱上方过去”,我们就可以把轨迹的优化范围限定在如右图所示的,可以到达全局最优点的位置。形式化地来说,我们可以定义一个好的轨迹应当满足的特质:$\tau:S\to A(\Xi,S)$,其中S是抽象的任务描述,而$\Xi$是可以解决任务的轨迹的集合,$A(\Xi,S)$就代表了轨迹的属性,比如在上例中就是从冰箱门上方运动过去。我们就可以隐式地描述出原先轨迹集合$\Xi$的一个子集:$\Xi_A\subseteq \Xi$,我们从这个好轨迹集合中选取第二阶段优化的初始值,这样就可以避免局部最优的情况。所以总体流程就为$S\to A(\Xi,S)\to \xi\in\Xi_A\to\xi^*$。
我们继续回到这篇文章,我们如果想优化$f_g(\xi_i)$,我们希望能够最大化motion generation success。文章使用了把第i次迭代时的Goal Set描述为了概率分布$p_i$,那么这一步其实就是在迭代计算$p_{i+1}$的过程,那么第i+1次迭代的时候,我们选取的目标抓点就是$g_{i+1}=\arg\max(p_{i+1})$,文章使用的赌博机算法(Bandit Algorithm)不再过多叙述,是一个简单的RL算法。
在线抓取合成
这一部分主要应用了CASE2018所提出的ISF算法,也就是从初始的有限抓取集合G出发,通过优化的方式在线合成更多质量更高的抓取点。优化的目标函数为:
$$
f_{grasp}(g)=f_{isf}(g)+\gamma f_{collision}(g)
$$
ISF主要就是最大化夹爪和物体的接触面积,这件事情是通过对夹爪上的采样表面点和法向量,并且优化接触点位置处的法向量和距离得到的,ISF算法因为本身也设计到很多理解和推导,暂时不在这里描述。
并且此处有:$f_{collision}(g)=f_{hand_obstacle}+\beta f_{obstacle}(g)$,这里的$f_{obstacle}$就是在CHOMP中的碰撞损失,而$f_{hand_obstacle}$指的就是在抓取的过程中,我们不希望robot的手部和待抓取的物体会出现任何的碰撞。
最终这篇文章提出的算法如下,每次迭代的时候,先用带约束的CHOMP创建轨迹,然后迭代更新Goal Set的分布,然后选取其中成功率最大的一个grasp作为goal,然后使用C-Space ISF方法来优化这个选取的grasp,使其抓取的成功率更大。

CHOMP_and_related_works