We propose DexArt, a task suite of Dexterous manipulation with Articulated object using point cloud observation. We experiment with extensive benchmark methods that learn category-level manipulation policy on seen objects. We evaluate the policies’ generalizability on a collection of unseen objects, as well as their robustness to camera viewpoint change.
Video
Abstract
To enable general-purpose robots, we will require the robot to operate daily articulated objects as humans do. Current robot manipulation has heavily relied on using a parallel gripper, which restricts the robot to a limited set of objects. On the other hand, operating with a multi-finger robot hand will allow better approximation to human behavior and enable the robot to operate on diverse articulated objects.
To achieve this goal, we propose a new benchmark for Dexterous manipulation with Articulated objects (DexArt) in a physical simulator. In our benchmark, we define multiple complex manipulation tasks, and the robot hand will need to manipulate diverse articulated objects within each task. Our main evaluation will focus on the generalizability of the learned policy on unseen articulated objects. This is very challenging given the high degrees of freedom of both hands and objects.
We achieve such generalization using Reinforcement Learning (RL) with 3D representation learning. We perform extensive studies on RL with 3D point cloud inputs and provide new insights on how 3D representation learning affects decision making.
Methods
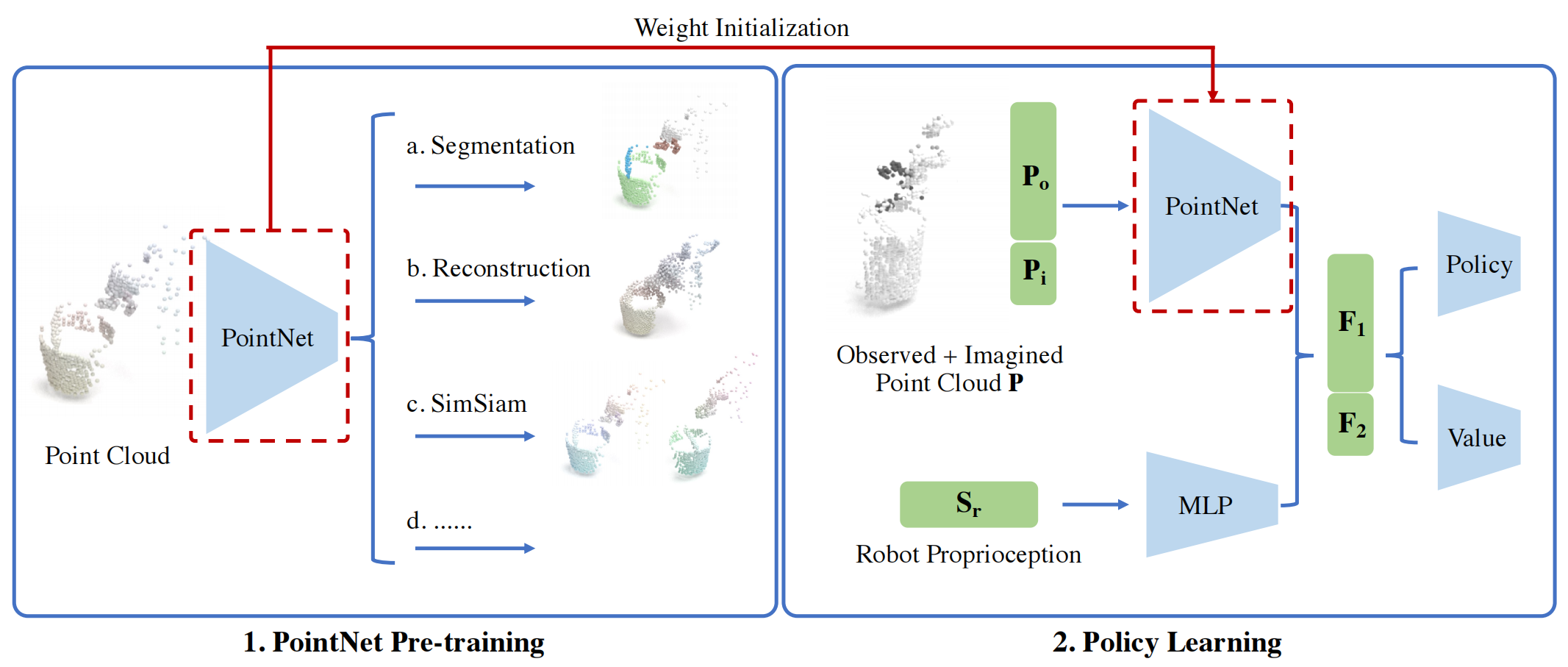
Overview. We adopt PPO algorithm with PointNet backbone to learn dexterous manipulation on articulated objects. We use pre-training to facilitate the policy learning process. (1) The PointNet is pre-trained on perception-only tasks, which includes segmentation, reconstruction, SimSiam, etc. (2) The pre-trained PointNet weight is then used to initialize the visual backbone in PPO before RL training.
Turn on Different Faucets
Open the Lids of Different Laptops
Lift Different Buckets
Open the Lids of Different Toilets
Segmentation Visualization during RL
Our Findings
We experiment and benchmark with different methods to provide several insights:

Object part reasoning is essential. 3D visual understanding helps policy learning.
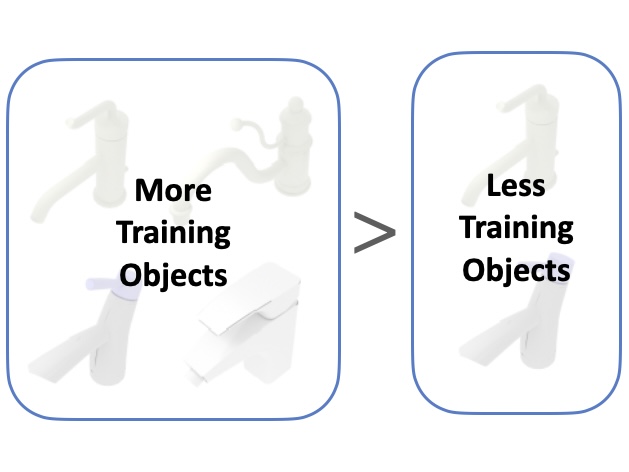
RL with more diverse objects leads to better generalizability.
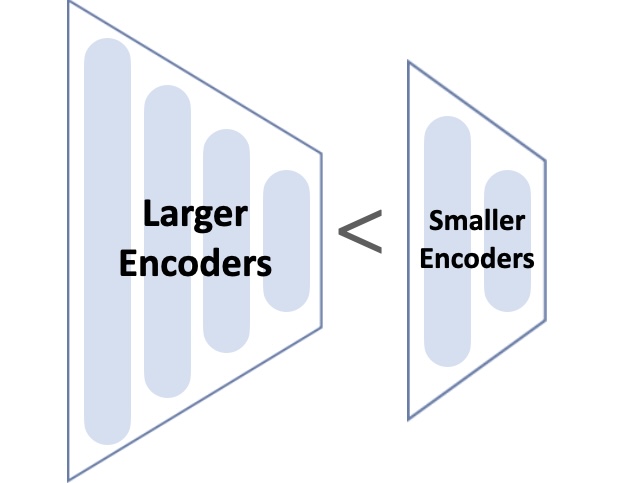
Large encoders may not be necessary for RL training to perform dexterous manipulation tasks.
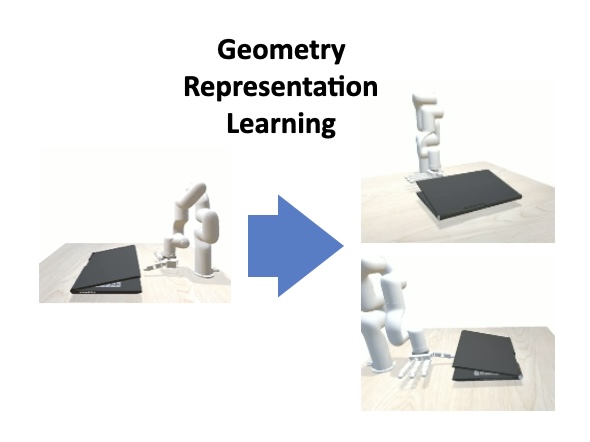
Geometric representation learning with PointNet feature extractor brings strong robustness to the policy against camera viewpoint change.
Robustness Experiments
We experiment with the viewpoint change of camera in Laptop task to evaluate the robustness of policy based on PointNet and ResNet-18.
(i) PointNet policy shows great robustness against viewpoint change.
(ii) Success rate of the ResNet-18 policy suffers dramatically drop under novel viewpoints.
BibTeX
@inproceedings{
bao2023dexart,
title={DexArt: Benchmarking Generalizable Dexterous Manipulation with Articulated Objects},
author={Chen Bao and Helin Xu and Yuzhe Qin and Xiaolong Wang},
booktitle={Conference on Computer Vision and Pattern Recognition 2023},
year={2023},
url={https://openreview.net/forum?id=v-KQONFyeKp}
}This website template is borrowed from Nerfies